앞선 선형회귀(Linear Regression), 로지스틱 회귀(Logistic Regression)에 이어 오늘은 Softmax Regression과 ANN(Artificial Neural Network)에 대해 공부해보자!
Ⅰ. 이진 분류와 다중 클래스 분류
두 개의 선택지 중에서 정답을 고르는 문제를 이진 분류 문제(Binary Classification)이라고 한다.
세 개 이상의 선택지 중에서 정답을 고르는 문제에 사용하는 모델을 다중 클래스 분류 문제(MultiClass Classification)이라고 한다. 그리고 요때 사용하는 알고리즘이 Softmax Regression이다!!
Ⅱ. Softmax Regression
한 가지 예시를 들어서 이야기를 이어가보도록 하자.
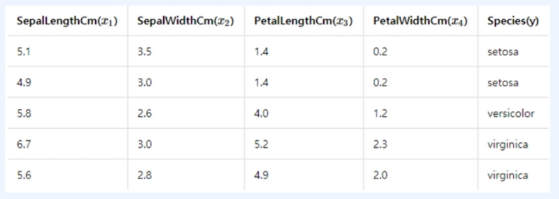
음... 쉽게 얘기하면 Softmax Regression은 Logistic Regression의 2개 클래스에 대한 확률값과는 다르게 각 클래스에 대한 "확률값"을 반환하게 된다. 물론, 각 확률값의 총합은 1이다.
소프트맥스 회귀는 `k`차원의 벡터에서 `i`번째 원소를 `z_i`, `i`번째 클래스가 정답을 확률을 `p_i`라고 하였을 때, 소프트맥스 함수는 `p_i`를 다음과 같이 정의한다.
$$p_i = \frac{e^{z_i}}{\sum_{j=1}^{k}e^{z_j}}\; for\;i\;=1,2,\cdots,k$$
위의 예시에서는 `k=3`이므로 `z=[z_1, z_2, z_3]`이니, 아래와 같이 다시 쓸 수 있겠다!!
$$softmax(z) = [\frac{e^{z_1}}{\sum_{j=1}^3 e^{z_j}} \frac{e^{z_2}}{\sum_{j=1}^3 e^{z_j}} \frac{e^{z_3}}{}] = [p_1, p_2, p_3] = \hat y = 예측값$$
쉽게 말해 Logistic Regression과 Softmax Regression 모두 들어오는 입력 데이터가 어떤 class에 해당하는지 분류하는 문제에 사용되지만, Logistic Regression의 경우 주로 class가 2개인 경우(=Binary Classification), Softmax Regression의 경우 주로 class가 3개 이상인 경우(=MultiClass Classification)에 적용되고 총합을 1로 스케일링 해준다고 생각하자!
한 가지 우리가 고려해봐야할 문제가 있다.
이제까지의 Softmax Regrssion 설명을 들어보면 들어오는 데이터를 softmax function을 적용하여 특정 개수의 class에 해당하는 확률값으로 반환함을 알 수 있다. 이때 들어오는 input 데이터의 수와 나가는 각 class의 확률값이 맞지 않는경우 어떻게 해야할까? 입력을 어떻게 잘 했다고 쳐도 가중치와 편향 업데이트를 위해 오차를 구해야할텐데 어떻게 구할까?
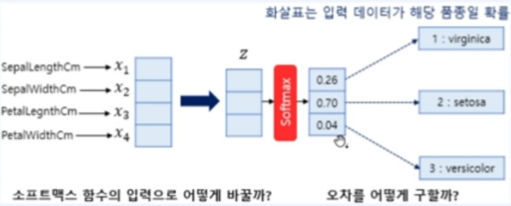
결론부터 말하자면 인위적으로 softmax function의 입력에 맞는 형태로 바꿔줘야한다.
첫 번째 고려할 점인 들어오는 input data를 softmax function의 input형태로 어떻게 바꿔줘야 하냐?!
아래와 같이 각 input data와 각 class label에 해당하는 가중치의 곱을 합하면 된다.

`z_1`이라는 class에 대해서만 따져보도록 하겠다.
`x_1`과 `z_1`에 대한 가중치를 `w_1`, `x_2`과 `z_1`에 대한 가중치를 `w_2`, `x_3`과 `z_1`에 대한 가중치를 `w_3`, `x_4`과 `z_1`에 대한 가중치를 `w_4`라고 한다면 우리가 원하는 것은 `x_1 \times w_1 + x_2 \times w_2 + x_3 \times w_3 + x_4 \times w_4`이고, 이것이 4개 입력이 가지는 `z_1`의 가중치 합이라고 할 수 있겠다. (요것이 뒤에 설명할 ANN의 근본방식이기도 하다!)
두 번째 고려할 점인 오차를 어떻게 정할 것인지는 아래 그림을 보면 바로 이해가 된다!
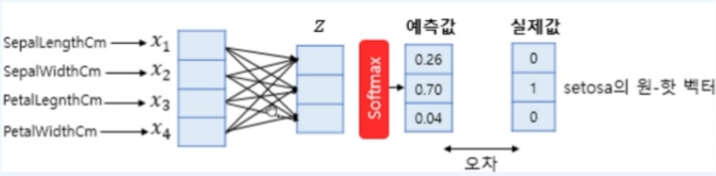
즉, softmax function을 통해 구한 값은 입력값에 대한 각 class label의 예측값이고 실제 정답을 one-hot vectorize시킨 것과 비교하여 그 차이를 구하는데 이것을 오차로 사용한다. 이 오차들이 가중치와 편향을 업데이트하는데 사용된다.
Softmax Regression의 forward 연산을 시각화해본다면 아래와 같이 그릴 수 있겠다.
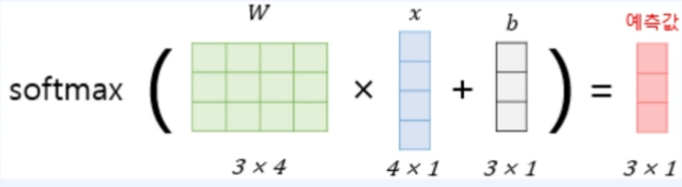
여기서 forward 연산이라 함은 가중치가 업데이트 되는 방향으로의 연산을 말한다.
(아마 머신러닝 카테고리쪽에서 다룰거라 생각하지만 역방향 연산인 Back Propagation도 존재한다.)
softmax regression의 cost function으로는 Logistic Regression과 동일한 '크로스 엔트로피 함수'를 사용한다.
$$ cost(W) = -\frac{1}{n}\sum_{i=1}^{n}\sum_{j=1}^{k} y_j^{(i)}log(p_j^{(i)})$$
Ⅲ. Artificial Neural Network (ANN)
ANN은 흔히 말하는 인공신경망을 일컫는 말이다.
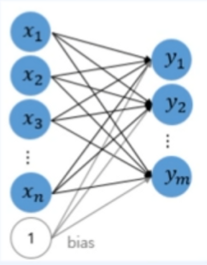
인공지능을 공부하다보면 위와 비슷한 형태의 그림을 자주 보게 될 것인데, 저 구조를 가진 것들을 우리는 ANN이라고 한다. 신경망을 행렬과 벡터 연산으로 이해할 수 있다면, 이해하기에 더 쉬울 것이다!
우리가 `파라미터`라고 부르는 것은 이 가중치들을 말하는 것이고, 파라미터 개수는 가중치들의 갯수라고 생각하자.
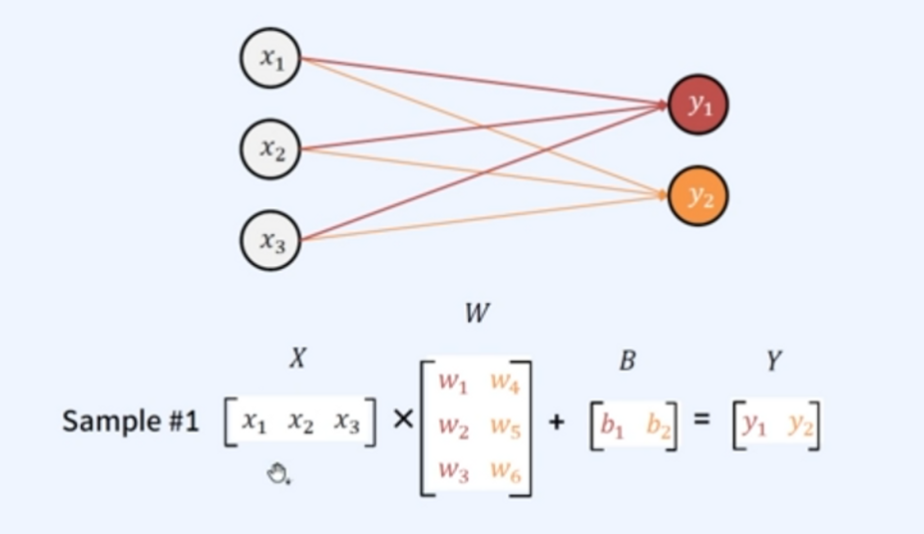
위 그림의 파라미터 개수는 몇개인가? 입력이 3개, 출력이 2개이므로 이에 상응하는 가중치의 개수는 총 6개이므로 파라미터 개수는 6개라 할 수 있다.
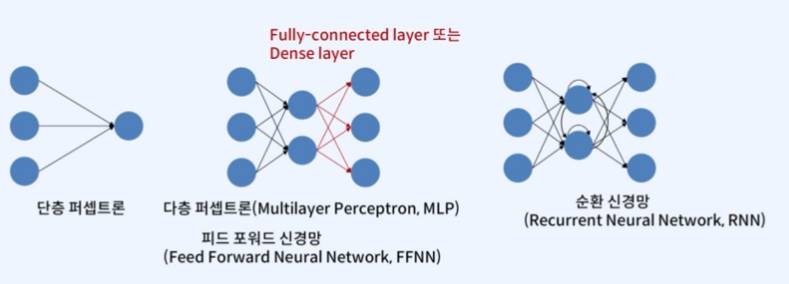
그렇다면 다층 퍼셉트론은 무엇일까?
피드 포워드 신경망 (Feed Forward Neural Network)는 앞서 말했던 입력층에서 출력층 방향으로 향하는 신경망을 말하는데 이것의 대표적인 예시가 다층 퍼셉트론(Multi Perceptron, MLP)라고 한다.
(퍼셉트론과 신경망의 차이는 신경쓰일 수 있는데 전혀 당황하지 말자. 가장 마지막에서 한번에 정리할테니!)
요것들의 종류에는 다양한게 있는데 아래를 참고하자.
Ⅳ. 개념을 배웠으면 정리를 해야지!
개념을 배웠으면 실습으로 옮겨야한다!! 주어진 텍스트를 분류하는 task를 ANN으로 구현해보자!
import pandas as pd
import numpy as np
import torch
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.datasets import fetch_20newsgroups
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
newsdata = fetch_20newsgroups(subset = 'train')
num_labels = len(newsdata.target_names)
data = pd.DataFrame(newsdata.data, columns = ['email'])
data['target'] = pd.Series(newsdata.target)
print('결측값 여부 : ', data.isnull().values.any()) # 결측값 여부 : False
print('중복을 제외한 샘플의 수 : {}'.format(data['email'].nunique()))
print('중복을 제외한 주제의 수 : {}'.format(data['target'].nunique()))
# 중복을 제외한 샘플의 수 : 11314
# 중복을 제외한 주제의 수 : 20
newsdata_test = fetch_20newsgroups(subset='test', shuffle=True)
train_email = data['email']
train_label = data['target']
test_email = newsdata_test.data
test_label = newsdata_test.target
vocab_size = 10000
tfidf_vect = TfidfVectorizer(max_features=vocab_size)
train_tfidf_list = tfidf_vect.fit_transform(train_email).toarray().tolist()
test_tfidf_list = tfidf_vect.transform(test_email).toarray().tolist()
train_tfidf_tensor = torch.tensor(train_tfidf_list)
train_label_tensor = torch.tensor(train_label)
test_tfidf_tensor = torch.tensor(test_tfidf_list)
test_label_tensor = torch.tensor(test_label)
# nn.Linear(input_dim, output_dim) : 뉴런의 개수를 기재하므로서 층을 만듭니다. 각각 input_dim과 output_dim을 의미합니다.
class Perceptron(torch.nn.Module):
def __init__(self, tfidf_size, num_label):
super(Perceptron, self).__init__()
self.linear1 = torch.nn.Linear(tfidf_size, 1400)
self.relu = torch.nn.ReLU()
self.linear2 = torch.nn.Linear(1400, num_label)
def forward(self, tfidf_input):
hidden = self.linear1(tfidf_input)
relu = self.relu(hidden)
y_pred = self.linear2(relu)
return y_pred
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Perceptron(tfidf_size=vocab_size, num_label=num_labels)
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
train_dataset = torch.utils.data.TensorDataset(train_tfidf_tensor, train_label_tensor)
test_dataset = torch.utils.data.TensorDataset(test_tfidf_tensor, test_label_tensor)
train_DataLoader = torch.utils.data.DataLoader(train_dataset, shuffle=True, batch_size=4)
test_DataLoader = torch.utils.data.DataLoader(test_dataset, shuffle=False, batch_size=1)
model.train(True)
model.zero_grad()
for epoch in range(5):
epoch_loss = 0
for batch in train_DataLoader:
batch = tuple(t.to(device) for t in batch)
y_pred = model(batch[0])
loss = criterion(y_pred, batch[1])
epoch_loss += loss.item()
loss.backward()
optimizer.step()
model.zero_grad()
print(epoch, epoch_loss)
model.train(False)
model.eval()
pred = None
label = None
for batch in test_DataLoader:
batch = tuple(t.to(device) for t in batch)
with torch.no_grad():
y_pred = model(batch[0])
if pred is None:
pred = y_pred.detach().cpu().numpy()
label = batch[1].detach().cpu().numpy()
else:
pred = np.append(pred, y_pred.detach().cpu().numpy(), axis=0)
label = np.append(label, batch[1].detach().cpu().numpy(), axis=0)
pred = np.argmax(pred, axis=1)
※ 용어 정리
위에서 헷갈릴 수 있는 퍼셉트론과 신경망에 대해 정리를 해보자.
퍼셉트론은 Perception과 Neuron의 조합임을 알 수 있는데, 결국 직관적으로 생물학적 뉴런이 감각 정보를 받아서 문제를 해결하는 원리를 따라한 것을 말한다. 즉, 아래와 같다.

이에 반해 신경망은 퍼셉트론의 갯수가 늘어나고 input으로 들어오는 값들도 많아져서 그 규모를 크게 하여 많이 묶어놓은 것을 말한다.

'개발 > NLP' 카테고리의 다른 글
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (10) (0) | 2023.05.24 |
|---|---|
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (9) (0) | 2023.05.22 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (7) (0) | 2023.05.18 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (6) (0) | 2023.05.18 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (5) (0) | 2023.05.10 |



