0. 이전까지의 학습내용
컴퓨터는 데이터 속 문장의 경계, 단어의 경계, 어떤 내용은 포함하고 그렇지 않은지 기준을 명시에 주어야 한다.
주어진 데이터에 대해서 위와 같은 목적으로 특정 단위기준을 가지고 구분하는 작업을 "토큰화" 또는 "토크나이징"이라고 하고, 단위에 따라 단어 토큰화(Word Tokenization), 문장 토큰화(Sentence Tokenization)로 나누기도 한다.
토큰화는 직접 하는것 보다 만들어져있는 토크나이저를 사용하는 것이 효율적이며 그 중에서 Mecab이 보편적으로 빠르고 준수한 성능을 보인다.
토큰화가 끝난 데이터를 하나의 집합으로 담게 되는데 이를 Vocabulary, 혹은 vocab이라고 말하고 이 안에 든 단어들은 중복되지 않는다. 이들 각각의 단어에는 고유한 정수가 부여되고 이는 앞으로 입력된 모든 텍스트를 정수 시퀀스로 변환하기 위함이다. 이렇게 단어마다 고유한 정수를 부여하는 작업을 정수 인코딩(Integer Encoding)이라고 한다.
vocab을 만드는 동안 다음과 같은 문제가 생길수도 있다. 단어집합에 없는 단어가 데이터로 들어온 것!
이와 같은 문제를 OOV (Out of Vocabulary) 문제라고 하며 일괄적으로 특수한 토큰으로 대체한다. 통상적으로 <UNK> 토큰으로 대체하게 된다.
딥러닝 모델에서 문장 데이터를 다루기 위해서는 데이터를 행렬로써 인식시킬 필요가 있다. 행렬로 인식시키기 위해서는 각기 다른 문장의 길이를 맞춰줘야 하는데 이 작업을 패딩(Padding)이라고 하며 패딩 역시 <PAD> 특수토큰을 추가하여 작업한다.
( ※ 보통 vocab속 <PAD>를 0, <UNK>를 1로 놓는다. 더 많은 특수토큰에 대해선 이후에 따로 다루도록 하겠다. )
1. 벡터화(Vectorization)
벡터화는 크게 3가지 카테고리로 나눌 수 있을 것이다.
1. 벡터화에 신경망을 사용하지 않을 경우
- 단어에 대한 벡터화 : One-Hot Encoding(원 핫 인코딩)
- 문서에 대한 벡터화 : Document Term Matrix(DTM), TF-IDF
2. 벡터화에 신경망을 사용하는 경우
- 단어에 대한 벡터화 : 워드 임베딩(Word2Vec, GloVe, FastText, Embedding Layer)
- 문서에 대한 벡터화 : Doc2Vec, Sent2Vec
3. 문맥을 고려한 벡터화
- ELMo, BERT, GPT, T5, etc... ( Pre-trained Language Model의 시대가 도래했다...!! )
한... 2~3개 포스팅은 요 벡터화에 대해 작성하게 될 것 같다.
자, 그럼 가장 먼저 신경망을 사용하지 않는 벡터화를 알아보자!!
Ⅰ. 단어에 대한 벡터화 : One-Hot Encoding (원 핫 인코딩)
원-핫 인코딩은 전체 단어 집합의 크기를 벡터의 차원으로 가진다.
각 단어에 고유한 정수 인덱스를 부여한 후 해당 인덱스의 원소는 1, 나머지 원소는 0을 가지는 벡터가 만들어지는 것이다.
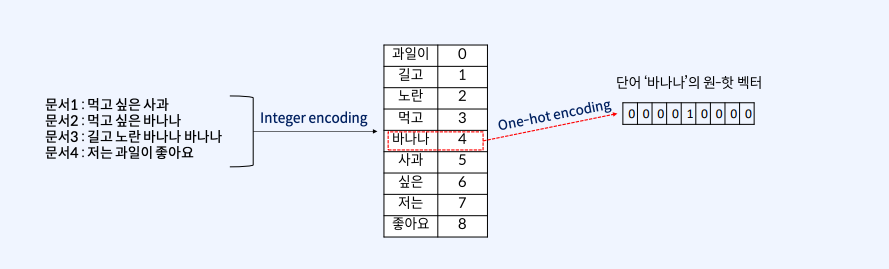
요렇게 만들어진 벡터는 해당 벡터의 차원이 우리가 만든 vocab의 크기라는 특징을 가진다!
다만, 이렇게 만든 원핫 벡터는 단어 벡터간 유의미한 유사도를 구할 수 없다. 이를 할 수 있는것이 이후에 자세히 소개할 워드 임베딩(Word Embedding)이다!
Ⅱ. 문서에 대한 벡터화 : Document Term Matrix(DTM)
DTM(Document Term Matrix)는 원핫 벡터와 마찬가지로 vocab의 크기를 가지며 대부분의 원소가 0을 가진다.
즉, 고냥 위에서 만든 원 핫 벡터를 표현을 바꿔 모아놓은 것이 DTM인것이다!
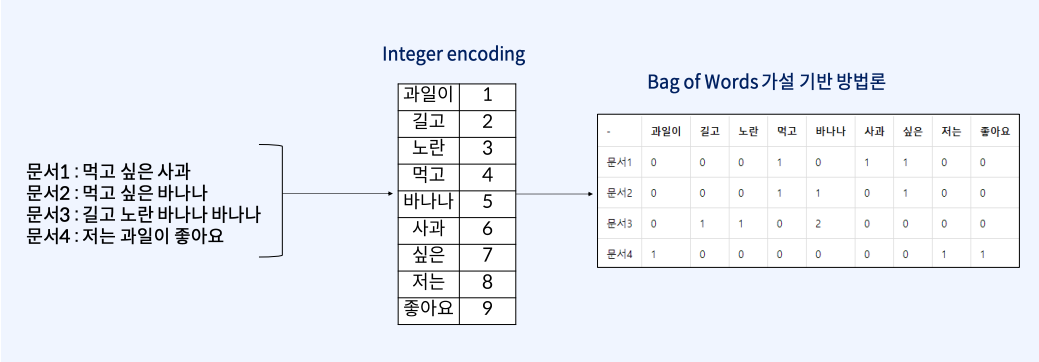
요게 이제 Bag of Words라는 것을 토대로 고안된 개념인데, Bag of Words(=BoW)를 직역하면 단어들의 가방을 의미하고, 이는 단어의 순서는 무시하고 오직 단어의 빈도수에만 집중하는 방법을 말한다.
Ⅲ. 문서에 대한 벡터화 : TF-IDF(Term Frequency-Inverse Document Frequency)
그렇다면 TF-IDF는 무엇일까?
앞서 알아본 DTM에서 추가적으로 중요한 단어에 가중치를 주는 방식을 말한다.
즉, TF-IDF 기준으로 중요한 단어는 값이 커지고, 중요하지 않은 단어는 값이 작아진다.
TF-IDF는 직역하면 '단어 빈도-역 문서 빈도'라고 할 수 있으며 TF와 IDF를 곱한 값이다.
문서의 유사도, 검색 시스템에서 검색 결과의 순위 등을 구하는 일에 쓰인다. 구성요소를 알아보자.
- TF(d,t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수.
- DF(t) : 특정 단어 t가 등장한 문서의 수.
- IDF(d,t) : DF(t)에 반비례하는 수.
우선, TF를 보자.
TF는 굉장히 심플하다. 특정문서 d에서의 특정 단어 t의 등장 횟수를 의미한다. 요말은 사실 DTM = TF라고 해도 된다!
그 다음, DF를 보자. (TF가 너무 간단하다ㅋㅋㅋㅋ) DF는 해당 단어가 몇 개의 문서에 등장했는지를 카운트한 값이다.
즉, 단어마다 존재하며 문서에 출현한 단어의 빈도수가 아닌 출현 여부를 카운팅한 값이라 생각하면 편하다.
마지막, IDF를 보자. IDF는 DF에 반비례하는 수 라고는 하나, 수식은 좀 다르다. 아래를 보자.
$$idf(d,t) = log(\frac{n}{1+df(t)})$$
분모에 1이 더해진 값은 분모가 0이 되지 않게 하기위함이고, log를 취해주는 이유는 IDF 값이 기하급수적으로 커질 수 있기 때문이다. 즉, 이는 희귀 단어들에 대한 가중치가 몰리는 현상을 방지하기 위함인 것이다.
구성요소를 전부 알아보았다. 이제 TF-IDF를 구해보자. 앞에서 TF와 IDF를 곱한 값이라고 했으니 계산 자체는 쉽다.
단, 주의해야할 점은 같은 단어라도 TF-IDF가 다르다는 점! 왜냐하면 해당 문서의 TF값에 영향을 받기 때문이다.
이렇듯 TF-IDF는 현업에서도 가장 많이 쓰이는 벡터화 방식이다. 아래 예제를 통해 한번 더 살펴보자.
# 깡으로 구현한 TF-IDF
import pandas as pd
from math import log
# TF를 구하는 함수
def tf(t, d):
return d.count(t)
# IDF를 구하는 함수
def idf(t):
df = 0
for doc in docs:
df += t in doc
return log(N/(df+1))
# TF와 IDF의 값을 곱하는 함수
def tfidf(t, d):
return tf(t,d)* idf(t)
if __name__ == "__main__":
# 빠른 실습을 위한 띄어쓰기 기준의 토큰화를 적용!
docs = [
'먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요'
]
# 총 문서의 수
N = len(docs)
# vocab 구축
vocab = list(set(w for doc in docs for w in doc.split()))
vocab.sort()
result_tf = []
for i in range(N):
result_tf.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
# tf 함수를 호출 : TF 값을 계산
result_tf[-1].append(tf(t, d))
tf_ = pd.DataFrame(result_tf, columns = vocab)
result_idf = []
# 각 단어에 대해서 idf값을 계산
for j in range(len(vocab)):
t = vocab[j]
# idf 함수를 호출 : IDF 값을 계산
result_idf.append(idf(t))
# IDF 출력
idf_ = pd.DataFrame(result_idf, index=vocab, columns=["IDF"])
result_tfidf = []
for i in range(N):
result_tfidf.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
# tfidf 함수를 호출 : TF-IDF 값 계산
result_tfidf[-1].append(tfidf(t,d))
# TF-IDF 행렬
tfidf_ = pd.DataFrame(result_tfidf, columns = vocab)# Sci-kit Learn을 이용한 DTM과 TF-IDF
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
vector = CountVectorizer()
# 코퍼스로부터 각 단어의 빈도수를 기록
print(vector.fit_transform(corpus).toarray())
# 각 단어와 맵핑된 인덱스 출력
print(vector.vocabulary_)
tfidfv = TfidfVectorizer().fit(corpus)
print(tfidfv.transform(corpus).toarray())
print(tfidfv.vocabulary_)'개발 > NLP' 카테고리의 다른 글
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (7) (0) | 2023.05.18 |
|---|---|
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (6) (0) | 2023.05.18 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (4) (1) | 2023.05.08 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (3) (0) | 2023.05.07 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (2) (0) | 2023.05.06 |



