이전 포스팅에 이어 로지스틱 회귀(Logistic Regression)에 대해 알아보자.
Ⅰ. 로지스틱 회귀 (Logistic Regression)
로지스틱 회귀는 2개의 선택지 중에서 정답을 고르는 문제에 사용되는 모델이다.
스팸 메일 분류나 합격, 불합격을 분류하는게 대표적인 예시라고 할 수 있다.
흔히 Binary Classification(이진분류)이라고 부르기도 하는데 막간을 이용해서 잠깐 설명해보면
Binary Classification은 분류문제의 종류중 하나이고 주어진 데이터를 2가지 label중 하나로 분류하는 task를 의미합니다! 그에 비해 Logistic Regression은 딥러닝 뿐 아니라 머신러닝/딥러닝을 통틀어서 가장 잘 사용되는 알고리즘이고, 주로 분류 task에 사용되는 겁니다! (혹여나 헷갈리실까봐ㅎㅎ)
로지스틱 회귀는 선형회귀와는 다르게 그래프가 직선으로 그어지지 않는다. 이 말은 선형회귀와는 다른 가설과 비용함수를 사용해야한다는 말이다!!
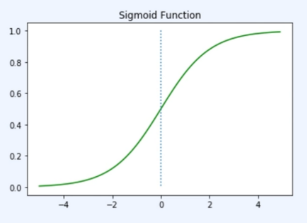
Ⅱ. Sigmoid Function
시그모이드 함수는 입력값이 커지면 1에 수렴하고 작으면 0에 수렴한다.
0부터 1까지의 범위중 하나의 값을 가지는데 여기서 출력값이 0.5 이상이면 1(True), 0.5 미만이면 0(False)으로 변환해서 이진분류에 적용할 수 있다!! 또한, 시그모이드 함수의 수식은 다음과 같다.
$$ \frac{1}{1+e^{-(Wx+b)}} = sigmoid(Wx+b) = \sigma(Wx+b)$$
로지스틱 회귀는 비용함수로 `MSE`를 사용하지 않는데, 사실 `MSE`가 분류 문제에 잘 사용되지 않는다.
그 이유에 대해선 머신러닝 카테고리에서 로지스틱 회귀를 다룰 때 자세히 설명하겠다!!
Ⅲ. CrossEntropy Function
로지스틱 회귀는 cost function으로 크로스 엔트로피 함수를 사용한다. 수식은 아래와 같다.
$$ if\;y=1 \rightarrow\;cost(H(x), y) = -log(H(x))\\if\;y=0 \rightarrow\;cost(H(x), y) = -log(1-H(x))\\cost(H(x),y) = -[ylogH(x)+(1-y)log(1-H(x))]$$
즉, `y`가 0이면 `ylog(H(x))`가 없어지고, `y`가 1이면 `(1-y)log(1=H(x))`가 없어지므로 이는 각각 `y`가 1일땡와 0일때의 식을 합친것이다! 요 수식을 전체 데이터 개수로 나눠 평균을 내면 비로소 완성이 된다.
$$cost(H(x), y) = -\frac{1}{n}\sum_{i=1}^{n}[y^{(i)}logH(x^{(i)})+(1-y^{(i)})log(1-H(x^{(i)}))]$$
정리하자면,
선형회귀의 가설은 `y=wx+b`
로지스틱 회귀의 가설은 `y= sigmoi d(wx+b)`
선형회귀의 손실함수는 Mean Squared Error, MSE
로지스틱 회귀의 손실함수는 Cross-Entropy
선형 회귀는 회귀 문제에 푸는 알고리즘으로 예측값이 연속적인 값이다.
로지스틱 회귀는 이진분류 문제에 푸는 알고리즘으로 예측값은 1 또는 0이다.
Ⅳ. 코드를 보자!
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
x_data = [[1,2], [2,3], [3,1], [4,3], [5,3], [6,2]]
y_data = [[0], [0], [0], [1], [1], [1]]
x_train = torch.FloatTensor(x_data)
y_train = torch.FloatTensor(y_data)
W = torch.zeros((2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
optimizer = optim.SGD([W, b], lr=1)
nb_epochs = 1000
for epoch in range(nb_epochs+1):
hypothesis = torch.sigmoid(x_train.matmul(W)+b)
cost = -(y_train * torch.log(hypothesis)+(1-y_train)*torch.log(1-hypothesis)).mean()
optimizer.zero_grad()
cost.backward()
optimizer.step()
if epoch % 100 == 0:
print('Epoch {:4d}/{} Cost: {:6f}'.format(epoch, nb_epochs, cost.item()))
prediction = hypothesis >= torch.FloatTensor([0.5])
print(prediction.tolist())
# [[False], [False], [False], [True], [True], [True]]
# -----------------------------------------------------
# y_data = [[0], [0], [0], [1], [1], [1]]'개발 > NLP' 카테고리의 다른 글
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (9) (0) | 2023.05.22 |
|---|---|
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (8) (0) | 2023.05.22 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (6) (0) | 2023.05.18 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (5) (0) | 2023.05.10 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (4) (1) | 2023.05.08 |



