오늘은 본격적인 워드 임베딩에 들어가기 앞서 가장 기초적인 몇가지 신경망에 대해 알아보고 정리하는 시간을 가지도록 하겠다~~ 그중에서도 선형회귀(Linear Regression)에 대해 알아볼 예정인데 (물론, 소프트맥스 회귀, 로지스틱 회귀, MLP 까지는 정리하려고 한다), 섬세한 내용은 머신러닝 카테고리에서 자세히 다룰예정이기 때문에 NLP 카테고리에서는 기본개념를 이해하는 정도로만 다루도록 하겠다. 자 가보자고~~
Ⅰ. 머신러닝?
기존의 프로그래밍은 원하고자 하는 프로세스가 명확하게 규정되어있고 이를 프로그래밍 언어로 옮긴 것이다. 즉, input이 있고, 명시적인 프로세스를 따라 ouput이 나온다는 말이다. 예를들자면 "더하기를 만드는 프로그램"은 a라는 변수와 b라는 변수가 왔을 때 2개의 변수를 더해 결론을 도출한다.
근데, 머신러닝 방식은 기존의 방식과 다르다. input으로 a와 b가 들어가도 프로세스가 어떻게 돌아가는지 모르고 자연스레 어떤 결과를 나오는지 예측하기 어렵다. 즉, 사람이 정의하기 어렵다는 말이다.
그래서, 입력(input)과 결과(output)가 있을 때 내부 프로세스라고 비유한 '과정'을 찾는것이 머신러닝의 목적이라 할 수 있겠다.
정리하자면, 위에서 계속 내부 프로세스라고 비유한 결론을 도출하는 과정을 사람이 찾아서 기계에 알려주는것이 이전까지의 프로그래밍 방식이면, 데이터를 매우 많이 주고 이를 통해 그 과정을 기계가 찾게 하는 방식을 머신 러닝이라고 말할 수 있다.
물론, 머신러닝도 굉장히 많은 알고리즘이 포함되어 있다. Neural Networks, Regularization, Rule System, Regression, 등의 큰 카테고리에서부터 내부적으로 다양한 알고리즘을 가지는데, (물론 딥러닝도 이에 포함된다) 이번 포스팅에서는 선형회귀(Linear Regression)에 대해 알아보자.
Ⅱ. 선형 회귀 (Linear Regression)
선형회귀란 무엇일까? 쉽게 말해 데이터를 반영하는 가장 적절한 선을 긋는 작업이라 할 수 있겠다.
선을 그으면?? 그 후엔 뭘 하지..? 선을 긋게된다는 것은 주어진 데이터로부터 상관관계를 모델링한것이라 볼 수 있기에 특정한 입력이 들어갔을때 이 모델에 해당하는 결괏값을 우리가 얻을 수 있게 되는 것이다!! 와우~

우리가 중학교때 일차 함수를 배웠다. `y=ax+b`와 같은 형태로말이다. 이것을 그대로 가져다 쓸 것이다.
같은 형태에서 `a`를 `w`로 바꾸고(어차피 변수라 문자가 바뀔뿐 같은 의미이다) 가중치라 부를 것이다.
또한 `b`를 `y`절편이라 부르던 것을 이제부터는 편향이라고 부르게 된다.
필자는 이것을 처음 이해할때 이런방식으로 생각했다. 데이터로부터 상관관계를 모델링 한다는것이 와닿지 않아 다음과 같이 생각했더니 그나마 낫더라.. ㅋㅋ 그게 무엇이냐면, 위의 그래프를 한번 보자. x값에 따른 y값이 여러개의 파란점으로 찍여있다. 이를 각각의 점으로 보지말고 마치 형광펜으로 저 점들이 지나가는 위치를 한번에 긋는다고 상상해보자. 그럼 엄청나게 두꺼운 면이 그려질 것이다. 이때 모니터에서 멀찍이 떨어져서 보자. 무한한 좌표계 상에서 가까이 보던 형광펜의 흔적이 한없이 뒤로가서 보면 어느순간 선으로 보일 것이다. 바로 이것!! (오히려 이해하기 어려운가...? 그렇다면 유감이다..)
다만, 이를 표현하는데에도 몇가지 고려할 사항이 있다. 아래그림을 보자.
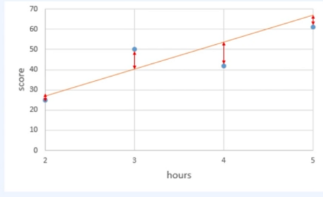
이 그림과 같이 4개 데이터를 관통하는 임의의 직선을 긋고 각 데이터에서의 거리를 보면 차이가 제각각이다.
이말은 즉슨 가장 적절한 직선을 표현하기 위해서는 수치적으로 표현하여 판단할 수 있어야 하고 이를 위해 오차(Error)라는 개념을 가져다 써야하는데 이 오차가 직선과 각 데이터까지의 거리를 나타낸다.
그렇다면 이 오차라는 것들을 그대로 사용할 수 있는가?
아니다. 데이터가 직선보다 위에 있다면 오차의 크기는 -값을 가질 것이고, 반대의 경우 +값을 가질 것이다.
만약 내가 운이 좋아서 아무렇게나 직선을 그엇는데 우연치 않게 총합이 0이 되버린경우 그 직선을 과연 최적의 경우라 할 수 있을까?
이러한 경우를 방지하기 위해 우리는 "평균 제곱 오차"라는것을 사용할 것이고 이는 Mean Squared Error (MSE)라고 하며 수식은 아래와 같다.
$$\frac{1}{n} \sum_{i=1}^{n}[y^{(i)}-H(x^{(i)})]^2$$
즉, 데이터의 개수가 `n`이라고 할 때 모든 오차를 제곱한 총합을 `n`으로 나누면 `MSE`값이 구해진다.
선형회귀는 `MSE`를 최소화하는 직선을 찾아내는 것이라 이해하자!
머신러닝에서는 실제값과 예측값에 대한 오차의 식을 Cost function이라고 한다.
다만, 사람에 따라 Objective function(목적 함수), Loss function(손실 함수)라고 표현하기도 하는데 기본적으로 같은 의미임을 알고있자! 많이 혼동한다.
인공 신경망은 기본적으로 Cost function을 최소화하는 `w`(가중치)와 `b`(편향)를 찾는 것이 목적이다!!
$$w, b \rightarrow minimize\;cost(w,b)$$
Ⅲ. Gradient Descent
이제 우리는 선형 회귀를 포함한 인공 신경망에서 cost function을 최소화하는 매개변수를 찾아야 한다.
바로 이때 사용되는 알고리즘을 옵티마이저(Optimizer)라고 한다. 많이들 들어봤을 경사하강법은 대표적인 옵티마이저 알고리즘이다~
경사하강법은 접선의 기울기 개념을 사용하고, 최적의 값을 향해서 매개변수를 반복적으로 업데이트한다.
cost function을 `w`에 대해 미분하면 접선의 기울기를 얻는다. 아이디어를 정리하자면 아래와 같다.
- 비용 함수(Cost function)을 미분하여 현재 `w`에서의 접선의 기울기를 구한다.
- 접선의 기울기가 낮은 방향으로 `w`의 값을 변경한다. 이때 변경될 `w`값은 현재의 `w`값 - 접선의 기울기이다.
- 위의 1,2번을 충분히 반복한다.
이를 수식으로 표현하면 아래와 같다.
※ `\alpha`는 Learing Rate라는 값인데 미분한 값이 너무 크면 오른쪽 혹은 왼쪽으로 핑퐁될 수 있어서 그 정도를 조절하기 위해 넣는 값이다. 주로 0에서 1 사이의 값이 들어간다.
$$ W := W - \alpha \frac{\partial}{\partial W}cost(W)$$
Ⅳ. 머신러닝의 모델링 과정
머신러닝 모델은 기본적으로 다음과 같은 3가지 과정을 거친다.
- 학습하고자 하는 가설(Hypothesis)을 세운다.
- 가설의 성능을 측정할 수 있는 손실 함수(Loss Function)을 정의한다.
- 손실 함수 L을 최소화 할 수 있는 학습 알고리즘을 설계한다.
위의 단계에 맞춰 선형회귀를 복습해보자.
1) 학습하고자 하는 가설(Hypothesis)을 세운다.
$$y = wx +b$$
이때 `x`와 `y`는 주어지는 입력 데이터와 타겟 데이터이고, `w`와 `b`는 파라미터라고 부르며 이제부터 학습을 진행해 적절한 값을 찾게 될 것이다.
2) 가설의 성능을 측정할 수 있는 손실 함수(Loss function)을 정의한다.
$$\frac{1}{n} \sum_{i=1}^{n}[y^{(i)}-H(x^{(i)})]^2$$
손실함수는 여러가지 형태로 정의될 수 있지만 가장 대표적으로 사용되는 것이 오늘 알아본 `MSE` 이다.
3) 손실 함수 L을 최소화 할 수 있는 학습 알고리즘을 설계한다.
머신러닝 모델은 처음엔 랜덤값으로 파라미터(`w`와 `b`)를 초기화한 후에 적절한 값으로 계속해서 업데이트한다.
이때 업데이트 하는 방법을 최적화 기법(optimization)이라고 하며, 대표적인 것이 경사 하강법(Gradient Descent)이다.
경사 하강법은 현재 step의 파라미터에서 손실 함수의 미분값에 러닝 레이트 `\alpha`를 곱한 만큼 빼서 다음 스텝의 파라미터 값으로 지정한다.
Ⅴ. 코드를 보자!
pytorch를 활용한 선형회귀 구현예제를 보자!
# 선형 회귀 구현
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 현재 실습하고 있는 파이썬 코드를 재실행해도 다음에 같은 결과가 나오도록 랜덤 시드(random seed)를 준다.
torch.manual_seed(1)
x_train = torch.FloatTensor([[1],[2],[3]])
y_train = torch.FloatTensor([[2],[4],[6]])
# 가중치 W를 0으로 초기화하고 학습을 통해 값이 변경되는 변수임을 명시함.
W = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)
optimizer = optim.SGD([W, b], lr=0.01)
nb_epochs = 1999
for epoch in range(nb_epochs+1):
# H(x) 계산
hypothesis = x_train*W + b
# cost 계산
cost = torch.mean((hypothesis - y_train)**2)
# cost로 H(x) 업데이트
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} W: {:.3f}, b: {:.3f} Cost: {:.6f}'.format(epoch, nb_epochs, W.item(), b.item(), cost.item()))'개발 > NLP' 카테고리의 다른 글
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (8) (0) | 2023.05.22 |
|---|---|
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (7) (0) | 2023.05.18 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (5) (0) | 2023.05.10 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (4) (1) | 2023.05.08 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (3) (0) | 2023.05.07 |



