저번 포스팅에 이어 본격적으로 Word2Vec에 대해 공부해봅시다!!
Ⅰ. Word2Vec
반복해서 이야기하지만 컴퓨터가 신경망을 이용해 단어에 대한 작업을 하기위해서는 단어를 '벡터화'시킬 필요가 있습니다! 이를 위해 사용하는 방법론은 Word2Vec, GloVe, FastText등 많지만 이번 포스팅에선 Word2Vec에 집중해보죠!
Word2Vec은 임베딩 그 자체에만 집중하는 신경망 모델인데요, 크게 2가지로 분류가 됩니다!
주변단어들로부터 중심단어를 예측하는 CBoW와 반대로 중심단어들로부터 주변 단어를 예측하는 Skip-gram이 있습니다! 과거는 어땠을지 몰라도 현재는 CBoW보다는 Skip-gram이 좋은 성능을 낸다고 합니다. 요 Skip-gram도 구버전과 신버전으로 나뉜다고 하는데, 이것에 초점을 두고 공부해보도록 하죠😊😊

Ⅱ. Skip-gram (구 버전)
옛날식(?) Skip-gram을 살펴봅시다.
Skip-gram은 중심 단어들로부터 주변 단어를 예측한다고 했었죠? 하나의 중심 단어에서 어느정도 범위까지 주변 단어를 보는지 범위지정이 먼저 필요합니다! 요 범위지정을 window size라고 하는데요, 다음 사진을 이해해보자구요!

위의 그림과 같이 하나의 중심단어로부터 사용자가 정한 window size만큼 바라보면 embedding table을 구성할 수 있죠!
이렇게 구성된 embedding table을 이용해 실제 정답에 해당하는 벡터와 비교하여 오차를 측정하고 이를 역전파시켜 가중치를 업데이트하게 된답니다!

즉, Skip-gram은 모든 존재하는 단어 중 하나의 단어를 예측하는 Softmax 문제와 동일한 것이죠!
전체적인 과정을 보면 다음과 같습니다!
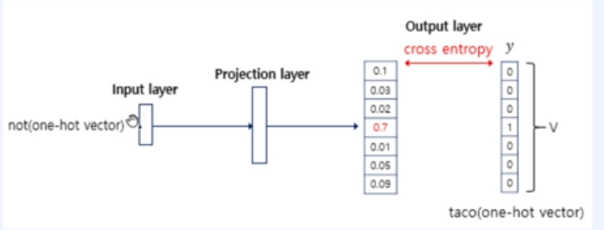
물론, 이러한 방식으로 구현하지는 않는다고 하네요. 그 이유는 속도이슈 때문인 것 같습니다.
Ⅲ. Skip-gram (신 버전)
이제 신버전을 살펴볼까요?
과거의 skip-gram은 모든 존재하는 단어 중 하나의 단어를 예측하는 Softmax를 활용한 Multi-Class Classification 문제로 바라볼 수 있었는데요, 이제는 방식을 좀 바꿔봅시다. 기존의 방식의 input word와 target word를 같이 입력으로 주고 이들이 올바르게 올 수 있는지 유사도를 검출하기로 한 것인데요, 이러한 접근은 Skip-gram의 접근방식을 Binary-Classification으로 바꾸어 바라보게 됩니다.
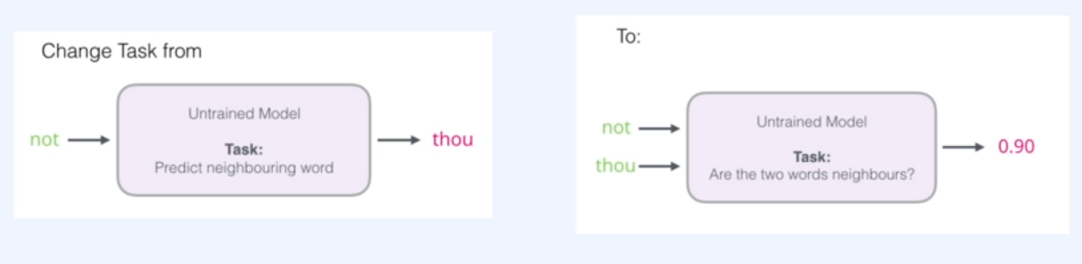
이를 위한 작업을 하기전에 역시나 데이터셋을 갖추어야겠죠.
원래의 방식이 input word와 target word를 쌍으로 주어졌다면 이제는 input word와 output word(=target word)를 주고 주변단어가 맞는지 아닌지 (0과 1)를 레이블해줍니다.
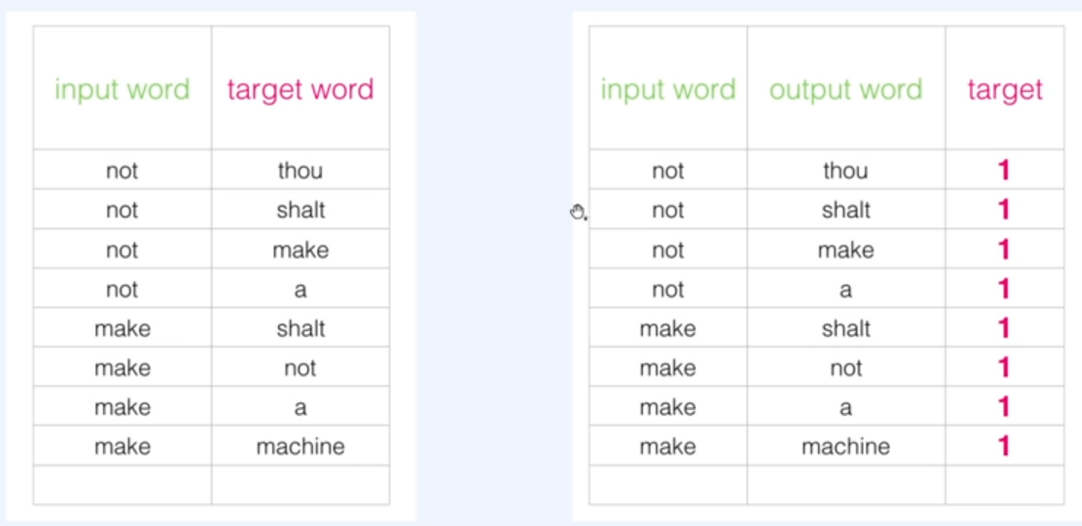
이렇게 구성한 데이터셋은 target이 1밖에 없겠죠? 그렇기에 거짓을 의미하는 샘플들을 추가해주어야 합니다. 이를 Negative Sample이라고 하고 전체 데이터셋에서 랜덤으로 추가해주게 됩니다.

이러한 방식으로 준비된 Embedding table을 2개 준비해줍니다.
한 테이블은 중심단어를, 다른 테이블은 주변 단어를 위한 테이블이에요!!
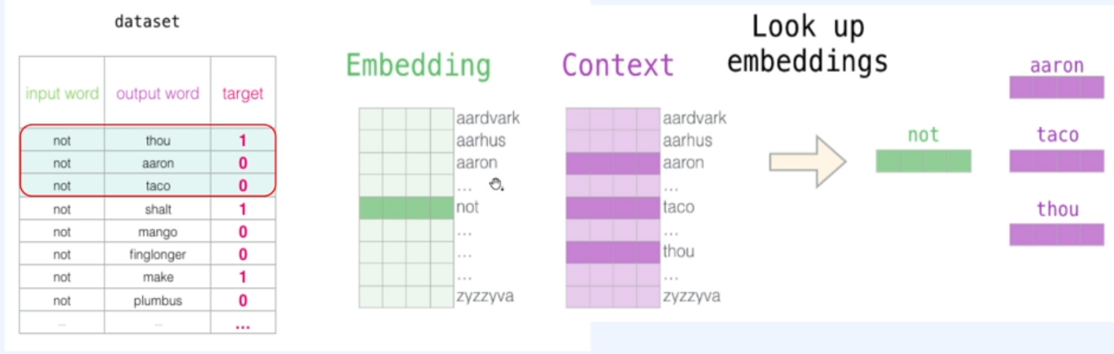
이제 이들을 활용해 중심단어와 주변단어의 내적을 수행하고 도출된 예측값과 실제값의 오차를 계산하여 역전파를 수행합니다!
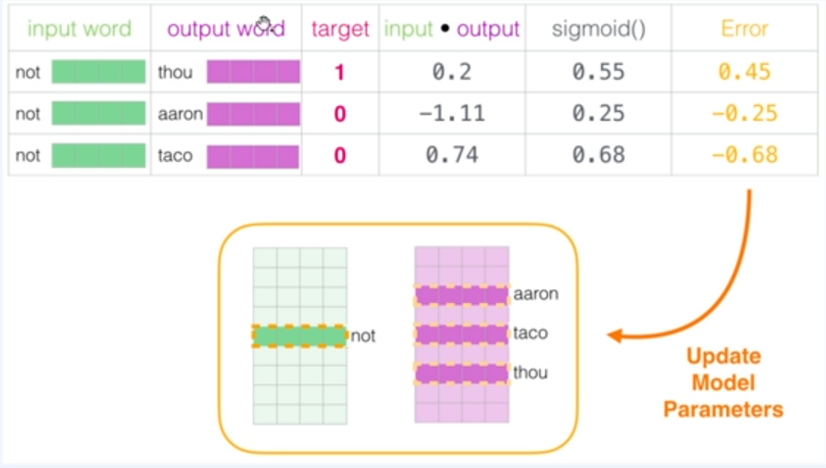
이러한 방식으로 진행되는것이 신 버전 Skip-gram이고 정확히는 Skip-Gram with negative Sample(SGNS)라고 한답니다. 요 방식은 Embedding vector의 차원을 사용자가 정해야 하는것이 특징이고 현재는 CBoW보다 SGNS를 사용하는것을 선호한다고 합니다. 또한 작은 윈도우 크기(2~7)을 가질수록, 높은 유사도를 가지게 되지만 경우에 따라 반의어도 포함될 수 있습니다. 반면에 큰 윈도우 크기(7~25)를 가지면 관련 있는 단어들을 군집하는 효과를 나타내게 된다고 하네요.
Ⅳ. 예제를 보자구요!
# 영어에 대한 Word2Vec
import re
from lxml import etree
import urllib.request
import zipfile
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize, sent_tokenize
from gensim.models import Word2Vec
from gensim.models import KeyedVectors
urllib.request.urlretrieve("https://raw.githubusercontent.com/GaoleMeng/RNN-and-FFNN-textClassification/master/ted_en-20160408.xml", filename="ted_en-20160408.xml")
targetXML = open('ted_en-20160408.xml', 'r', encoding='UTF8')
target_text = etree.parse(targetXML)
# xml 파일로부터 <content>와 </content> 사이의 내용만 가져온다.
parse_text = '\n'.join(target_text.xpath('//content/text()'))
# 정규 표현식의 sub 모듈을 통해 content 중간에 등장하는 (Audio), (Laughter) 등의 배경음 부분을 제거.
# 해당 코드는 괄호로 구성된 내용을 제거.
content_text = re.sub(r'\([^)]*\)', '', parse_text)
# 입력 코퍼스에 대해서 NLTK를 이용하여 문장 토큰화를 수행.
sent_text = sent_tokenize(content_text)
# 각 문장에 대해서 구두점을 제거하고, 대문자를 소문자로 변환.
normalized_text = []
for string in sent_text:
tokens = re.sub(r"[^a-z0-9]+", " ", string.lower())
normalized_text.append(tokens)
# 각 문장에 대해서 NLTK를 이용하여 단어 토큰화를 수행.
result = [word_tokenize(sentence) for sentence in normalized_text]
for line in result[:3]: # 샘플 3개만 출력
print(line)
model = Word2Vec(sentences=result, vector_size=100, window=5, min_count=5, workers=4, sg=0)
# vector_size = 워드 벡터의 특징 값. 즉, 임베딩 된 벡터의 차원.
# window = 컨텍스트 윈도우 크기
# min_count = 단어 최소 빈도 수 제한 (빈도가 적은 단어들은 학습하지 않는다.)
# workers = 학습을 위한 프로세스 수
# sg = 0은 CBOW, 1은 Skip-gram.
model_result = model.wv.most_similar("man")
print(model.wv["man"])
model.wv.save_word2vec_format('eng_w2v') # 모델 저장
loaded_model = KeyedVectors.load_word2vec_format("eng_w2v") # 모델 로드
model_result = loaded_model.most_similar("man")# 한국어에 대한 Word2Vec
import urllib.request
from konlpy.tag import Mecab
from gensim.models.word2vec import Word2Vec
import pandas as pd
import matplotlib.pyplot as plt
from gensim.models import Word2Vec
from gensim.models import KeyedVectors
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt", filename="ratings.txt")
train_data = pd.read_table('ratings.txt')
# NULL 값 존재 유무
print(train_data.isnull().values.any())
train_data = train_data.dropna(how = 'any') # Null 값이 존재하는 행 제거
print(train_data.isnull().values.any()) # Null 값이 존재하는지 확인
# 정규 표현식을 통한 한글 외 문자 제거
train_data['document'] = train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
# 불용어 정의
stopwords = ['도', '는', '다', '의', '가', '이', '은', '한', '에', '하', '고', '을', '를', '인', '듯', '과', '와', '네', '들', '듯', '지', '임', '게']
# 형태소 분석기 mecab을 사용한 토큰화 작업 (다소 시간 소요)
mecab = Mecab()
tokenized_data = []
for sentence in train_data['document']:
temp_X = mecab.morphs(sentence) # 토큰화
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
tokenized_data.append(temp_X)
model = Word2Vec(sentences = tokenized_data, vector_size = 100, window = 5, min_count = 5, workers = 4, sg = 0)
# 완성된 임베딩 매트릭스의 크기 확인
print(model.wv.vectors.shape)
print(model.wv.most_similar("최민식"))
print(model.wv['최민식'])
model.wv.save_word2vec_format('kor_w2v') # 모델 저장'개발 > NLP' 카테고리의 다른 글
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (12) (0) | 2023.06.04 |
|---|---|
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (11) (0) | 2023.05.24 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (9) (0) | 2023.05.22 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (8) (0) | 2023.05.22 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (7) (0) | 2023.05.18 |



