지난 포스팅에선 Word2Vec에 대해 알아봤죠, 이번에는 FastText에 대해 알아봅시다.
반복해서 말하지만 Word2Vec, FastText 둘다 신경망을 이용한 단어의 벡터화 방법론입니다😊
Ⅰ. FastText
Word2Vec의 개량 알고리즘으로 Subword를 고려한 알고리즘입니다!
이는 Word2Vec의 한계점에서부터 파생된 개념인데 컴퓨터는 단어가 생긴게 다르면 아예 다른단어로 인식해버립니다.
eat과 eating이 공통적으로 eat을 가지고 있더라고 할 지라도 말이죠...!
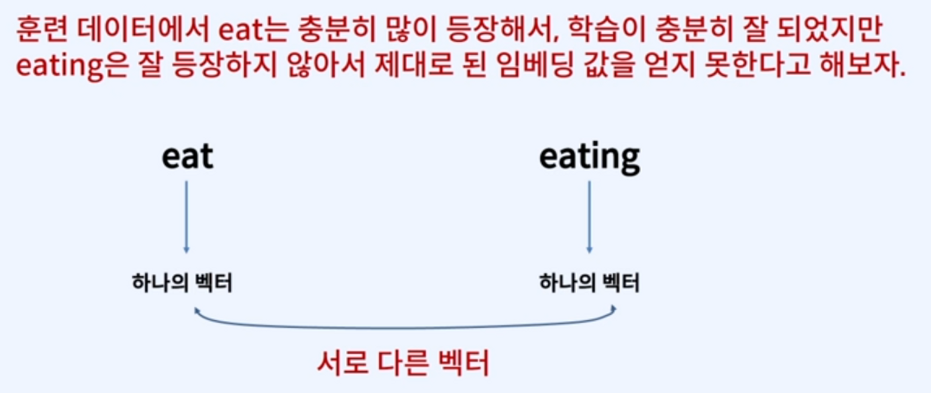
즉 위 그림처럼 형태학적인 특징이 단어의 의미고려에 반영되지 않습니다...
그외에도 OOV(Out of Vocabulary)라고 하는 문제도 있어요.

그래서 FastText는 Subword라는 개념을 도입하게 되는데요, 조금 더 자세히 살펴봅시다.
단어를 Character 단위 n-gram으로 간주하고 사용자가 적절한 n을 정해줍니다.
그리고 이 수치를 따라 다음과 같이 단어를 분리하게 됩니다.

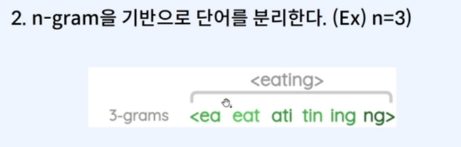
n-gram 기반이라고 하는 것은 단어의 첫글자부터 n개씩 묶음을 짓는것과 동일합니다.
다만, n의 숫자에 따라 아래와 같이 분리가 달라지니 적절하게 정해주세요.

이와 같이 훈련 데이터를 n-gram 기반으로 분리하였다면 트레이닝 방식은 SGNS와 동일합니다.
다만, Word가 아닌 subwords들이 최종 학습 목표이고 이들의 합을 Word의 vector로 간주하게 됩니다.

이제부터는 SGNS와 동일한 방식이나 자세한 설명은 생략하도록 하겠습니다!
중심단어의 벡터가 구해진 이후의 학습과정은 이전 포스트를 참조해주세요😎
Ⅱ. 이런 방식이 왜 Word2Vec보다 뛰어난가?
Word2Vec과 다르게 하나의 target word에 대해 단어들을 적절한 길이로 자르고 이들을 벡터화 시킨 후 총합하는 과정을 거치게 됩니다. 그 과정에서 target word와 조금 다른 형태를 가진 word들도 유사성을 가지게 된다는 결과를 도출할 수 있는것이죠. 그림으로 이해하는편이 빠를겁니다.
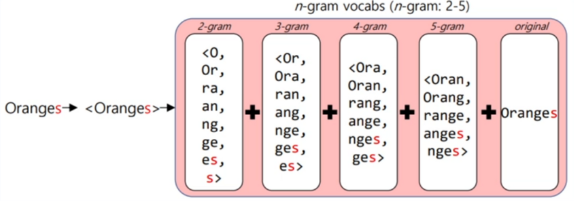
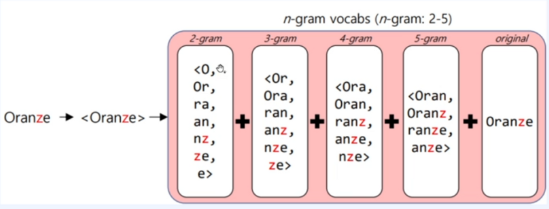
아, 그리고 단어의 양 끝에 특수한 문자 <와 >를 왜 추가하냐면요 단어가 단어를 포함하는 경우때문에 그래요.
예를 들면 where과 her 같은 경우를 말하죠. 그러니 이러한 경우를 구분해주기 위해서 추가하는 거랍니다~
캬.. 원리가 기똥차지 않나요?! 전 보면서 감탄했다구요!!
이렇게 진행하게 되면 전체 Word가 아닌 Subword들의 유사도가 반영됨을 확인할 수 있어요.
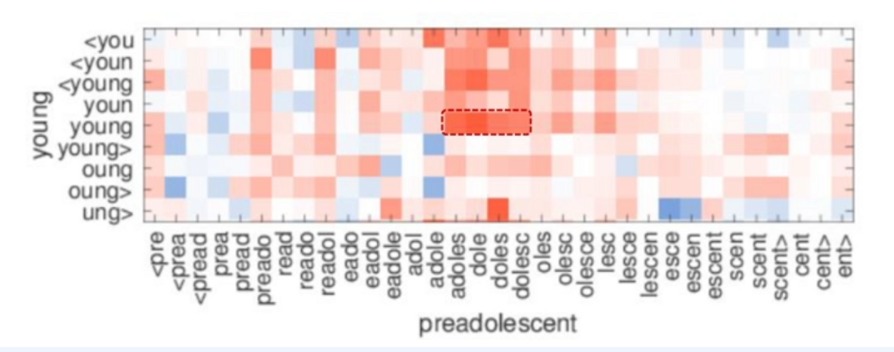
Ⅲ. 한국어의 FastText
한국어는 영어와 다르게 다양한 용언 형태를 가지죠. 그래서 사실 Word2Vec으로 하기에는 영어보다 더 명확한 한계가 존재합니다. 그래서 n-gram 단위를 자모단위로 진행하기도 해요. hgtk라는 라이브러리와 meta(전 facebook)의 fasttext를 사용하게 되는데, 이것은 실습코드를 보면서 이해하시면 될 겁니다.

Ⅳ. 실습을 잘 보고 이해를 해봅시다!
# colab으로 작업한 예제를 옮긴것입니당
from gensim.models import FastText
fasttext_model = FastText(result, vector_size=100, window=5, min_count=5, workers=4, sg=1)
fasttext_model.wv.most_similar('overacting')
fasttext_model.wv.most_similar('memorry')
fasttext_model.wv.most_similar("electrofishing")# colab으로 작업한 예제를 옮긴것입니당.
# facebook의 fasttext와 hgtk 라이브러리를 활용했습니당.
import hgtk
urllib.request.urlretrieve("https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/naver_shopping.txt", filename="ratings_total.txt")
total_data = pd.read_table("ratings_total.txt", names=['ratings', 'reviews'])
print("전체 리뷰 개수 : ", len(total_data)) # 전체 리뷰 개수 출력
# 한글인지 체크
hgtk.checker.is_hangul('ㄱ')
# 한글이 아닌 입력에 대해서는 에러 발생.
hgtk.letter.decompose('1')
# 결합할 수 없는 상황에서는 에러 발생
hgtk.letter.compose('ㄴ', 'ㅁ', 'ㅁ')
def word_to_jamo(token):
def to_special_token(jamo):
if not jamo:
return '-'
else:
return jamo
decomposed_token = ''
for char in token:
try:
# char(음절)을 초성, 중성, 종성으로 분리
cho, jung, jong = hgtk.letter.decompose(char)
# 자모가 빈 문자일 경우 특수문자 -로 대체
cho = to_special_token(cho)
jung = to_special_token(jung)
jong = to_special_token(jong)
decomposed_token = decomposed_token + cho + jung + jong
# 만약 char(음절)이 한글이 아닐 경우 자모를 나누지 않고 추가.
except Exception as exception:
if type(exception).__name__ == 'NotHangulException':
decomposed_token += char
# 단어 토큰의 자모 단위 분리 결과를 추가
return decomposed_token
def tokenize_by_jamo(s):
return [word_to_jamo(token) for token in mecab.morphs(s)]
mecab = Mecab()
print(mecab.morphs('선물용으로 빨리 받아서 전달했어야 하는 상품이었는데 머그컵만 와서 당황했습니다.'))
from tqdm import tqdm
tokenized_data = []
for sample in total_data['reviews'].to_list():
tokenzied_sample = tokenize_by_jamo(sample) # 자소 단위 토큰화
tokenized_data.append(tokenzied_sample)
def jamo_to_word(jamo_sequence):
tokenized_jamo = []
index = 0
# 1. 초기 입력
# jamo_sequence = 'ㄴㅏㅁㄷㅗㅇㅅㅐㅐ'
while index < len(jamo_sequence):
# 문자가 한글(정상적인 자모)이 아닐 경우
if not hgtk.checker.is_hangul(jamo_sequence[index]):
tokenized_jamo.append(jamo_sequence[index])
index = index + 1
# 문자가 정상적인 자모라면 초성, 중성, 종성을 하나의 토큰으로 간주.
else:
tokenized_jamo.append(jamo_sequence[index:index+3])
index = index + 3
# 2. 자모 단위 토큰화 완료
# tokenized_jamo = ['ㄴㅏㅁ', 'ㄷㅗㅇ', 'ㅅㅐㅇ']
word = ''
try:
for jamo in tokenized_jamo:
# 초성, 중성, 종성의 묶음으로 추정되는 경우
if len(jamo)==3:
if jamo[2] == '-':
# 종성이 존재하지 않는 경우
word = word + hgtk.letter.compose(jamo[0], jamo[1])
else:
# 종성이 존재하는 경우
word = word + hgtk.letter.compose(jamo[0], jamo[1], jamo[2])
# 한글이 아닌경우
else:
word = word + jamo
# 복원 중 에러 발생시 초기 입력 리턴.
# 복원이 불가능한 경우 ex) 'ㄴ!ㅁㄷㅗㅇㅅㅐㅇ'
except Exception as exception:
if type(exception).__name__ == 'NotHangulException':
return jamo_sequence
# 3. 단어로 복원 완료
# word : '남동생'
return word
import fasttext
with open('tokenized_data.txt', 'w') as out:
for line in tqdm(tokenized_data, unit=' line'):
out.write(' '.join(line)+'\n')
model = fasttext.train_unsupervised('tokenized_data.txt', model='cbow')
model.save_model('fasttext.bin')
model = fasttext.load_model('fasttext.bin')
model[word_to_jamo('남동생')] # ㄴㅏㅁㄷㅗㅇㅅㅐㅇ
# get_nearest_neighbors()는 타겟 벡터와 가장 유사도가 높은 벡터를 뽑아줍니다. 두번째 인자값인 k값은 몇개의 벡터를 뽑아줄지 경정합니다!
model.get_nearest_neighbors(word_to_jamo('남동생'), k=10)
def transform(word_sequence):
return [(jamo_to_word(word), similarity) for (similarity, word) in word_sequence]
print(transform(model.get_nearest_neighbors(word_to_jamo('남동생'), k=10)))
print(transform(model.get_nearest_neighbors(word_to_jamo('남동쉥'), k=10)))
print(transform(model.get_nearest_neighbors(word_to_jamo('남동셍ㅋ'), k=10)))'개발 > NLP' 카테고리의 다른 글
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (13) (0) | 2023.08.03 |
|---|---|
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (12) (0) | 2023.06.04 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (10) (0) | 2023.05.24 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (9) (0) | 2023.05.22 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (8) (0) | 2023.05.22 |



