Pandas Tutorials Pandas is a Python library for data manipulation and analysis, and can be conveniently used to process large amounts of data. An introduction to the basic use of Pandas. Examples and explanations refer to pandas official documentation.Ref link : https://codetorial.net/pandas/index.html # Importing module
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
Pandas Object Tutorials
Series : 레이블을 가지는 1차원 어레이
DataFrame : 레이블 갖는 행x열 구조의 2차원 어레이
s = pd.Series([1,2,3,4,5,6])
t = pd.Series([1,2,3,4,5,6.3])
print(s)
print(t)
s = pd.Series([1,2,3,4.5,5,6], index=['a', 'b', 'c', 'd', 'e', 'f'])
s
dates = pd.date_range('20230112', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(dates)
print(df)
df2 = pd.DataFrame({'A': 1.,
'B': pd.Timestamp('20130102'),
'C': pd.Series(1, index=list(range(4)), dtype='float32'),
'D': np.array([3] * 4, dtype='int32'),
'E': pd.Categorical(["test", "train", "test", "train"]),
'F': 'foo'})
print(df2)
print(df2.dtypes)
df3 = pd.read_csv('./assets/pandas_ex01.csv', header=None)
df3
df4 = pd.read_csv('./assets/pandas_ex02.csv', header=0)
df4
df5 = pd.read_csv('./assets/pandas_ex02.csv', index_col=0)
df5
Pandas Viewing Data
df.head()
df.tail()
df.index()
df.columns()
df.to_numpy()
df.describe()
df.T()
df.sort_index()
df.sort_values()
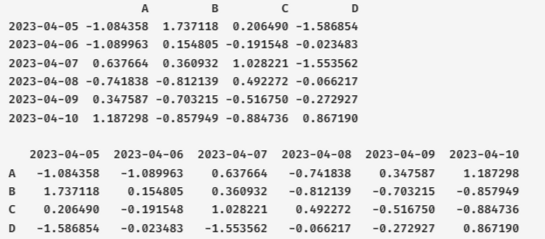
dates = pd.date_range('20230405', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
df
df.head(2)
df.tail(4)
df.index
df.columns
df.to_numpy()
df.describe()
print(df)
print()
print(df.T)
df.sort_index(axis=1, ascending=False)
df.sort_values(by='B')
Pandas Data Selection
df.loc()
df.iloc()
df.at()
df.iat()
df.isin()
np.random.seed(0)
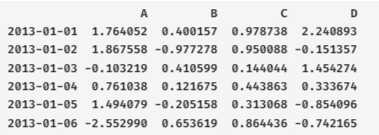
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(dates)
print(df)
# 열 선택하기
print(df['A'])
#print(df.A)
print(type(df['A']))
# 행 선택하기
print(df[0:3])
# 레이블로 선택하기
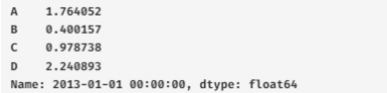
print(df.loc[dates[0]])
print(df.loc[:, ['A', 'B']])
print(df.loc['20130104', ['A', 'B']])
# A 0.761038
# B 0.121675
# Name: 2013-01-04 00:00:00, dtype: float64
df.loc[dates[0], 'A']
# 1.764052345967664
df.at[dates[0], 'A']
# 1.764052345967664
print(df)
print()
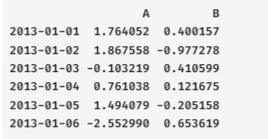
print(df.iloc[3]) # df.iloc[row position, col position]
print(df)
print()
print(df.iloc[2:4, 0:3])
print(df)
print()
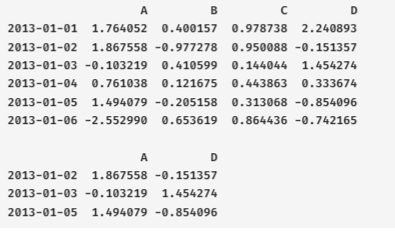
print(df.iloc[[1,2,4], [0, 3]])
print(df)
print()
print(df.iloc[5, 3])
print(df)
print()
print(df.iat[5, 3])
print(df)
print()
print(df.A > 2)
print(df)
print()
print(df[df>1])
df2 = df.copy()
df2['E'] = ['one', 'one', 'two', 'three', 'four', 'three']
print(df2)
print()
print(df2[df2['E'].isin(['two', 'four'])]) # Filtering
s1 = pd.Series([1, 2, 3, 4, 5, 6], index=pd.date_range('20130102', periods=6))
print(s1)
print()
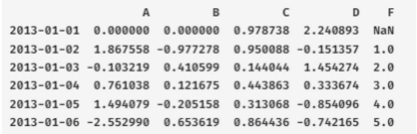
df['F'] = s1
print(df)
df.at[dates[0], 'A'] = 0
print(df)
df.iat[0, 1] = 0
print(df)
df.loc[:, 'D'] = np.array([5] * len(df))
print(df)
df2 = df.copy()
df2[df2 > 0] = -df2
print(df2)