Ⅰ. 인공지능, 머신러닝, 딥러닝
인공지능, 머신러닝, 딥러닝의 관계

1.1 머신러닝
머신러닝, 다른말로 기계학습이라고 하는 기법이다. 직관적으로 머신이 학습하는걸 의미하는데 어떻게 학습하는지는 전통적인 프로그램의 운용방식과 비교해보면 차이점이 명확하다.
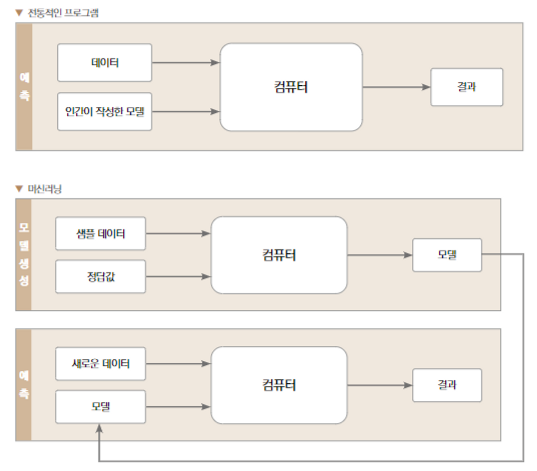
위처럼 전통적인 프로그램의 경우 사람이 각각의 테스크에 관여를 하게 되지만 머신러닝 알고리즘을 활용한 경우 입력값과 해당 정답값에 대한 결괏값을 입력할 경우 그 사이 관계를 찾아서 알고리즘이 새로운 프로그램을 만듭니다. 이후 새로운 데이터가 주입될 때마다 값을 예측하고 관계를 조정하여 최적의 관계를 추론하게 됩니다. 즉, 머신러닝은 아래와 같은 단계를 밟아갑니다.
- 머신러닝 알고리즘으로 입력된 데이터간의 관계를 정함.
- 관계를 바탕으로 새로운 프로그램(모델)을 만들게 됨.
- 새로운 데이터가 주어졌을 때 결과를 예측함.
그렇기 때문에 머신러닝에는 수많은 데이터가 필요합니다.
1.2 딥러닝
딥러닝, 다른말로 심층학습이라고 하는 기법이다. 딥러닝은 인간의 두뇌 작동방식을 본떠 개발된 것으로 아래와 같이 입력층과 출력층 사이에 은닉층을 두어 인간의 신경망처럼 작동시킵니다.
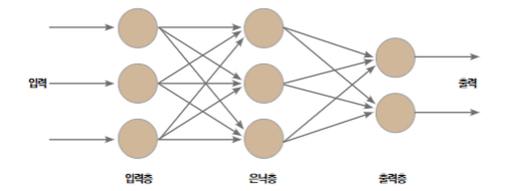
딥러닝은 머신러닝(이하 ml)의 방법 중 하나입니다.
1.3 머신러닝 기법
머신러닝에는 지도학습, 비지도 학습, 강화 학습이라는 3가지 범주가 존재합니다.

- 지도학습
- 입력값과 그에 대한 정답을 사용해 이 둘의 관계를 분석하고 예측하는 모델을 만듭니다.
- 회귀문제와 분류문제로 나뉩니다.
- 회귀문제(Regression) : 예측 결괏값이 연속성을 띠는 경우로 실수형으로 결과를 표현합니다.
- 분류문제(Classification) : 예측 결괏값이 비연속적인 경우입니다.
- 분류 종류를 클래스(Class)라고 합니다.
- 분류 종류가 2개일 경우 이진분류(Binary Classification)이라고 합니다.
- 분류 종류가 3개 이상일 경우 다중분류(Multiple Classifation)이라고 합니다.
- 비지도 학습
- 정답이 없는 데이터로만 학습합니다.
- 군집화(Clustering) : 비슷한 데이터끼리 묶어주는 방법입니다.
- 변환(Transformation) : 목적에 따라 데이터를 다른 형태로 변환하는 방법입니다.
- 연관(Association) : 장바구니 분석이라고도 하며 추천시스템에서 이용되는 방법입니다.
1.4 머신러닝 프로세스
머신러닝은 주어진 문제를 풀면서 세부내용에 따라 적절한 알고리즘과 풀이방식을 채택해야 합니다.
전체과정은 아래와 같습니다.
- 데이터 수집
- 데이터 전처리
- 모델 학습
- 모델 평가
- 모델 배포
그리고 위와 같은 과정을 MLOps(Machine Learning Operation)라고 부릅니다.
1.5 머신러닝 핵심 라이브러리
머신러닝에 사용되는 유용한 라이브러리는 굉장히 많습니다. 종류는 아래와 같습니다.
- Numpy : 다차원 배열에 대한 빠른 처리를 지원
- Pandas : 넘파이 기반으로 구현한 라이브러리. 인간 친화적인 자료구조를 제공해 데이터를 넘파이보다 쉽게 읽고 변형할 수 있다.
- Sci-kit learn : 데이터 분석 및 머신러닝 관련 기능을 지원하는 강력한 라이브러리
- Matplotlib : 시각화 라이브러리
- Seaborn : 맷플롯립 기반으로 구현한 라이브러리. 좀 더 직관적인 사용방식을 가진다.
- Scipy : 수학, 통꼐, 신호처리, 이미지 처리, 함수 최적화에 사용되는 강력한 데이터 과학 라이브러리
- Theano : 수학 표현식, 특히 행렬 값을 조작하고 평가하는 라이브러리
1.6 피쳐 엔지니어링 기법
피처 엔지니어링은 모델 학습에 입력할 데이터를 더 풍성하고 가치있게 만드는 작업입니다.
인공지능 업계에 굉장히 유명한 말이 있습니다.
➡️ Garbage in, garbage out
쓰레기 같은 데이터가 들어가면 쓰레기 같은 결과가 나온다는 의미입니다.
반대로 생각하면, 데이터가 좋을수록 더 좋은 결과를 얻을 수도 있습니다. 피처 엔지니어링은 머신러닝 프로세스에서 가장 중요한 과정이라고 해도 무리가 없으며, 그만큼 많은 시간과 노력을 들여야 합니다. 아래와 같이 간단히 정리하겠습니다.
기법 설명 사용 케이스
| 기법 | 설명 | 사용 케이스 |
| 결측치 처리 (Missing Value) |
데이터가 누락된 부분을 평균, 특정값등으로 채우는 기법 | 데이터 누락으로 인해 많은 데이터를 사용하지 못할 때 |
| 아웃라이어 처리 (Outlier) |
다른 데이터 무리들과는 크게 벗어나는 아웃라이어를 제거하거나 값을 조정해 튀는 데이터가 없도록 하는 기법 | 선형 모델과 같이 아웃라이어의 영향에 민감한 모델 |
| 바이닝 (Bining) |
연속된 수치로 된 데이터를 특정 구간으로 묶는 기법. | 오버피팅으로 인해 모델 성능이 문제될 때 |
| 로그 변환 (Log Transform) |
데이터에 로그를 씌워 왜곡된 데이터를 정규화하는 방법 | 데이터 형태가 왜곡되어 변환이 필요한 경우, 특히 선형모델 |
| 더미 변수 (One Hot Encoding) |
문자로 된 범주형 데이터를 0과 1을 사용하는 숫자형 데이터로 변경하는 기법 | 범주형 데이터 |
| 그룹핑 (Grouping) |
고윳값이 너무 많은 범주형 데이터를 특정그룹으로 묶는 기법. | 범주형 데이터에서 고윳값이 너무 많아 더미변수를 쓰기 곤란할 때 |
| 스케일링 (Scaling) |
변수의 데이터 범위가 다를 때 이를 일정하게 맞춰주는 기법 | 거리 기반으로 작동하는 모델(K-최근접 이웃, K-평균 군집화) |
| 날짜 추출 | 날짜 데이터에서 연/월/일 혹은 요일등을 추출해 필요한 정보만 사용하는 기법 | 날짜 데이터의 특정 속성이 중요한 역할을 할 때 |
| 텍스트 분할 | 텍스트로 된 변수에서 특정 부분의 단어를 빼오거나, 특정 기호가 들어간 부분을 기준으로 나누어, 필요한 항목만 추출하는 기법 | 텍스트 변수에 불필요한 정보가 많이 뒤섞여 있을 때 |
| 새로운 변수 창출 | 주어진 변수들을 이용해 새로운 변수를 계산해내는 기법. 단순하게는 변수간의 사칙연산등을 활용할 수 있다. | 데이터에 대한 백그라운드 지식이 있을 때 |
1.7 변수
프로그래밍에서 사용되는 변수 말고 통계학적으로 특성에 따라 다르게 구분할 수 있습니다.
- 독립변수(Independent Variable)
- 원인에 해당.
- 예측에 사용되는 재료와 같은 변수들이다.
- 피쳐(Feature)라고 불린다.
- 피쳐 변수(Feature Variable)이라고도 합니다.
- 종속변수(Dependent Variable)
- 결과에 해당.
- 예측을 하려는 대상과 같은 변수들이다.
- 목표(Target)
- 목표 변수(Target Variable)이라고도 합니다.
출처
데싸노트의 실전에서 통하는 머신러닝 교재 내용발췌
https://github.com/musthave-ML10/notebooks
GitHub - musthave-ML10/notebooks
Contribute to musthave-ML10/notebooks development by creating an account on GitHub.
github.com
'개발 > AI (ML, DL, DS, etc..)' 카테고리의 다른 글
| Pandas Tutorials [Notions : 1/12] (0) | 2023.05.01 |
|---|---|
| Matplotlib Tutorials [Notions : 1/9] (0) | 2023.04.30 |
| Numpy Tutorials 02 [Notion : 1/9] (0) | 2023.04.30 |
| Numpy Tutorials 01 [Notion : 1/4] (0) | 2023.04.30 |
| [파이썬, 딥러닝, 파이토치] #5 "Mnist 설계" (0) | 2022.03.27 |



