안녕하세요오~~~ Ash에요!😆😆
이전까지 머신러닝에 대한 기초적인 개념을 알아보았다면 오늘부터는 모델설계를 도전해보려고 합니다~~
Mahine Learning의 HelloWorld라고 일컬어지는 Mnist가 그 대상이에요!
바로 시작해볼까요?
기본적으로 제 개발환경은요
- GPU Device : RTX3070
- Python : 3.8.12
- pyTorch : 1.8.2
- CUDA : 11.1
위와 같습니다!
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torchvision import transforms, datasets
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using PyTorch version: {torch.__version__}, Device: {device}")
BATCH_SIZE = 32
EPOCHS = 10
train_dataset = datasets.MNIST(root="./data/MNIST", train=True, download=True, transform=transforms.ToTensor())
test_dataset = datasets.MNIST(root="./data/MNIST", train=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=BATCH_SIZE, shuffle=False)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28*28, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
# self.dropout_prob=0.5
def forward(self, x):
x = x.view(-1, 28*28) # Same to meaning of "Flatten"
x = self.fc1(x)
x = torch.sigmoid(x)
x = self.fc2(x)
x = torch.sigmoid(x)
x = self.fc3(x)
x = torch.softmax(x, dim=1)
return x
model = Net().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
def train(model, train_loader, optimizer, log_interval):
model.train()
for batch_idx, (image, label) in enumerate(train_loader):
image = image.to(device)
label = label.to(device)
optimizer.zero_grad()
output = model(image)
loss = criterion(output, label)
loss.backward()
optimizer.step()
if batch_idx%log_interval == 0:
print(f"Train Epoch: {EPOCHS} [{batch_idx*len(image)}/{len(train_loader.dataset)}({100. * batch_idx / len(train_loader):.0f}%)] \t Train Loss: {loss.item():.6f}")
def evalutate(model, test_loader):
model.eval()
test_loss=0
correct = 0
with torch.no_grad():
for image, label in test_loader:
image = image.to(device)
label = label.to(device)
output = model(image)
test_loss += criterion(output, label).item()
prediction = output.max(1, keepdim = True)[1]
correct += prediction.eq(label.view_as(prediction)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuraccy = 100. * correct / len(test_loader.dataset)
return test_loss, test_accuraccy
for epochs in range(1, EPOCHS+1):
train(model, train_loader, optimizer, log_interval=200)
test_loss, test_accuarccy = evalutate(model, test_loader)
print(f"[Epochs: {epochs}],\tTest Loss: {test_loss:.4f},\tTest Accuraccy: {test_accuarccy:.2f}%\n")요것이 제가 공부하는 Mnist DataSet을 활용한 MLP(Multi Layer Perceptron) Model입니다.
부분적으로 나누어 밑에서 설명드릴게요!
Ⅰ. Module Import
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torchvision import transforms, datasets- Numpy는 다들 아실거에요. 선형대수와 관련된 함수를 쉽게 사용할 수 있는 굉장히 유명한 라이브러리입니다.
- Matplotlib도 잘 아실텐데요, 함수의 실행결과 산출물에 대한 수치를 사람이 쉽게 이해할 수 있도록 시각화해주는 라이브러리 입니다.
- import torch -> pyTorch의 기본 모듈입니다.
- import torch.nn -> pyTorch Module중 ANN(Artificial Neural Network)Model을 설계할 때 필요한 함수를 모아놓은 모듈입니다.
- from torchvision import transforms, datasets -> 컴퓨티 비전 연구분야에서 자주 이용하는 torchvision 모듈 내 transforms와 datasets 함수를 가져옵니다.
Ⅱ. Device
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using PyTorch version: {torch.__version__}, Device: {device}")- GPU 장치가 존재하면 이를 활용하고 아니면 CPU를 활용하기 위한 device를 정해줍니다.
Ⅲ. HyperParameter와 Dataset Load
BATCH_SIZE = 32
EPOCHS = 10
train_dataset = datasets.MNIST(root="./data/MNIST", train=True, download=True, transform=transforms.ToTensor())
test_dataset = datasets.MNIST(root="./data/MNIST", train=False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=BATCH_SIZE, shuffle=False)- BATCH_SIZE : MLP 모델을 학습할 때 필요한 데이터 개수의 단위
- EPOCHS : 전체 데이터셋을 학습하는데 반복시킬 횟수
- datasets.MNIST( ~~ ) : 'torchvision'내 'datasets' 함수를 이용해 MNIST데이터셋을 다운로드 합니다.
- root : data가 저장될 장소를 지정합니다.
- train : 대상 데이터가 학습용이면 True, 아니면 False를 줍니다.
- download : 인터넷 상에서 다운로드해 이용할 것인지 정해줍니다.
- transform : 다운로드시 기본적인 전처리를 진행할 수 있습니다. transform=transforms.ToTensor()를 해줌으로써 tensor형태로 변환합니다.
Mini-Batch란?
데이터가 매우 많은 상황일때를 고려하여 전체 데이터를 더 작은 단위로 나누어서 해당 단위로 학습하는 개념.
이 단위를 미니 배치(Mini Batch)라고 합니다.
- data.DataLoader( ~~~ ) : 다운로드한 데이터셋을 Mini-Batch단위로 분리해 지정합니다.
- dataset : Mini-Batch 단위로 할당하고자 하는 데이터셋을 지정합니다.
- batch_size : Mini-Batch 1개 단위를 구성하는 데이터의 개수를 지정합니다.
- shuffle : 데이터의 순서를 섞고자 할 때 사용합니다. 잘못된 방향으로 학습하는 것을 방지하기 위해 데이터 순서를 섞는 과정을 진행합니다.
Ⅳ. Modeling
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28*28, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
# self.dropout_prob=0.5
def forward(self, x):
x = x.view(-1, 28*28) # Same to meaning of "Flatten"
x = self.fc1(x)
x = torch.sigmoid(x)
x = self.fc2(x)
x = torch.sigmoid(x)
x = self.fc3(x)
x = torch.softmax(x, dim=1)
return x
model = Net().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()- self.fc1 = nn.Linear(28*28*1, 512) -> 첫번째 Fully Connected Layer를 정의합니다.
MNIST 데이터를 Input으로 사용하기위해 28*28*1(가로픽셀 * 세로픽셀 * 채널수) 크키로 노드수를 설정하고 두번째 FC의 노드 수를 512개로 할 것이기 때문에 output노드수는 512개로 해줍니다. - self.fc2 = nn.Linear(512, 256) -> 두번째 Fully Connected Layer를 정의합니다.
- self.fc3 = nn.Linear(256, 10) -> 최종 output이 MNIST의 0~9중 하나의 숫자판별이기때문에 10개의 label이 나와야 하므로 10으로 정해줍니다.
- def forward(self, x) -> Net Class를 이용해 설계한 MLP모델의 Foward Propagation을 정의합니다.
- x.view(-1, 28*28) -> MLP model의 경우 1차원 벡터값을 입력으로 받아야 합니다. MNIST의 경우 28*28의 2차원 데이터이기 때문에 1차원데이터로 변환해 줄 필요가 있습니다. Flatten()의 역할과 같습니다. 첫번째 인자에 -1이 들어갈 경우 28*28의 2차원 텐서에서 ?? * 784의 형태로 바꾸어주라는 의미입니다. 즉, 1차원 데이터로 펼쳐주는 작업이죠.
- model = Net().to(device) -> 정의한 MLP모델을 기존에 설정한 device위에 올려놓습니다.
- optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
-> Back Propagation을 이용해 파라미터 업데이트시 이용하는 Optimizer를 정의합니다.
원래 SGD(Stochastic Gradient Descent)를 사용하지만 제 임의로 Adam을 넣었습니다.ㅎㅎ - lr = 0.01 -> 파라미터를 업데이트할 때 반영될 Learning Rate를 정해줍니다.
- criterion = nn.CrossEntropyLoss() -> MLP모델의 output과 one-hot encoding과의 loss를 계산하기위한 Loss Function입니다.
Ⅴ. Train Class
def train(model, train_loader, optimizer, log_interval):
model.train()
for batch_idx, (image, label) in enumerate(train_loader):
image = image.to(device)
label = label.to(device)
optimizer.zero_grad()
output = model(image)
loss = criterion(output, label)
loss.backward()
optimizer.step()
if batch_idx%log_interval == 0:
print(f"Train Epoch: {EPOCHS} [{batch_idx*len(image)}/{len(train_loader.dataset)}({100. * batch_idx / len(train_loader):.0f}%)] \t Train Loss: {loss.item():.6f}")- model.train() -> MLP모델을 학습 상태로 지정합니다.
- image = image.to(device)
- label = label.to(device)
-> Mini-batch 내에 있는 이미지 데이터와 레이블데이터를 학습시킬 device위로 올려줍니다. - optimizer.zero_grad()
-> 과거에 이용한 Mini-Batch 내에 있는 데이터들을 바탕으로 계산된 Loss의 Gradient가 optimizer에 할당되어있으므로 이를 초기화 시켜줍니다. - output = model(image)
-> 이미지 데이터를 MLP모델의 Input으로써 Output을 계산합니다. (학습시켜줍니다.) - loss = criterion(output, label)
-> 계산된 Output과 기존에 정의한 Loss Function을 이용해 Loss값을 계산합니다. - loss.backward()
-> Loss 값을 계산한 결과를 바탕으로 Back Propagation을 통해 계산된 Gradient값을 파라미터에 할당합니다. - optimizer.step()
-> optimizer에게 loss function을 효율적으로 최소화 할 수 있게 파라미터를 할당합니다.
Ⅵ. Evaluate Class
def evalutate(model, test_loader):
model.eval()
test_loss=0
correct = 0
with torch.no_grad():
for image, label in test_loader:
image = image.to(device)
label = label.to(device)
output = model(image)
test_loss += criterion(output, label).item()
prediction = output.max(1, keepdim = True)[1]
correct += prediction.eq(label.view_as(prediction)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuraccy = 100. * correct / len(test_loader.dataset)
return test_loss, test_accuraccy- model.eval() -> 학습이 완료된 MLP model을 평가상태로 지정합니다.
- with torch.no_grad():
-> Gradient를 통해 파라미터 값이 업데이트 되는 현상을 방지하기 위해 Gradient흐름을 억제합니다. - prediction = output.max(1, keepdim=True)[1]
-> 출력된 max는 (값, 인덱스)의 형태인데, 우리는 index가 필요하므로 [1]을 가져옵니다.
즉, 0~9 사이중 가장 수치가 높은 data의 label을 가져오는 거랍니다.
이후에는 모델을 epoch만큼 돌려보고 확인하는 코드이므로 자세한 설명은 생략하도록 하겠습니다!
제가 로컬에서 돌려본 결과를 보여드릴게요.
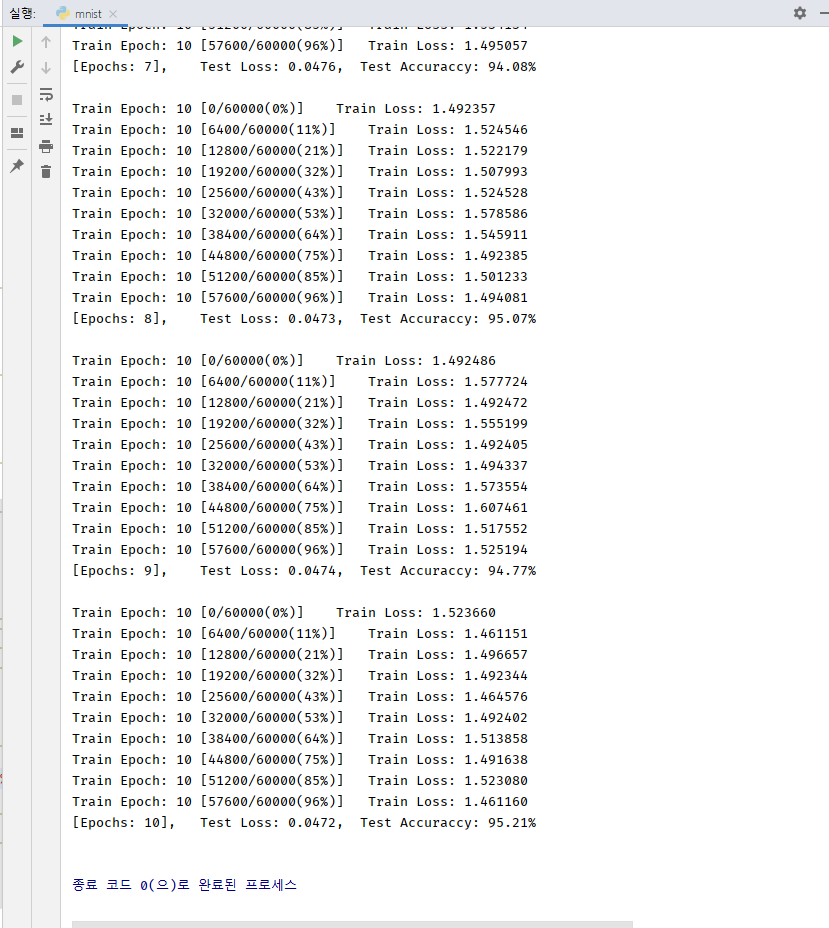
호오... 95%정도 나오는군요! SGD를 사용하였을 경우 약 90%정도의 정확도가 나오고 저는 Adam을 사용했기에 좀 더 높게 나온거랍니다.
'개발 > AI (ML, DL, DS, etc..)' 카테고리의 다른 글
| Numpy Tutorials 02 [Notion : 1/9] (0) | 2023.04.30 |
|---|---|
| Numpy Tutorials 01 [Notion : 1/4] (0) | 2023.04.30 |
| [파이썬, 딥러닝, 파이토치] #4 "Autograd" (0) | 2022.03.27 |
| [파이썬, 딥러닝, 파이토치] #3 "Tensor" (0) | 2022.03.26 |
| [파이썬, 딥러닝, 파이토치] #2 "개발환경 구성하기(feat. RTX3070)" (0) | 2022.03.25 |



