※ 본 블로그 포스트는 박지호님의 "Weekly NLP" 내용을 채용하여 개인공부를 기록한 포스트입니다.
원작자의 허가를 맡았으며 불법적인 공유가 아님을 미리 알립니다.
다양한 사람들을 만나다 보면 어떤 사람은 정말 나와 비슷하다(similar)고 느낄 때가 있습니다.
반대로 어떤 사람은 정말 거리감(distance)이 느껴지지요. 그렇게 느껴지는 것은 생각하는 방식의 비슷함 또는 차이일 수도 있고. 좋아하는 취미나 영화 일 수도 있고, 말투나 외형 같은 것일 수도 있습니다. 명확하게 설명할 수 없으나 다양한 요소(feature)들이 종합되어 유사성과 거리감의 느낌이 결정되는 것이겠지요.
Vector가 뭐더라...
Scalar(스칼라)가 무엇인지 아시나요? 크기만 있는 scalar는 우리가 주로 익숙한 숫자를 말합니다. 한 사람의 몸무게나 키, 컵에 들어있느 물의 양, 또는 음식에 포함된 칼로리의 양을 나타내는 숫자는 모두 scalar입니다.
그에 반해 Vector(벡터)는 방향도 포함합니다. 예를 들어, “여기서 편의점을 어떻게 가나요?”라고 물었을 때 그냥 “500m만 가시면 됩니다.”라고 말하면 뭔가 부족합니다. 방향도 같이 알려주어야 제대로 찾아갈 수 있죠. 즉, “여기서 왼쪽으로 돌아서 쭉 500m 가셔야 합니다.”라고 이야기 해야 완전한 정보가 됩니다.
vector는 몇 차원의 공간에서 표현되느냐에 따라 크게 달라집니다. 만약 우리가 고속도로를 타고 어딘가 가고 있다면 1차원 공간에 있는 것과 같습니다. 우리는 한 방향으로 전진만 하기 때문이죠. 평면의 지도를 보고 길을 찾는것은 2차원에 해당하고 3차원은 비행기 비행을 예시로 들 수 있습니다. 4차원 이상부터는 쉽게 상상하기 힘들지만 각 시간에 내가 어느 공간에 위치하느냐를 지속적으로 기록한다고 했을 때 대략적으로 유추해볼 수 있습니다.
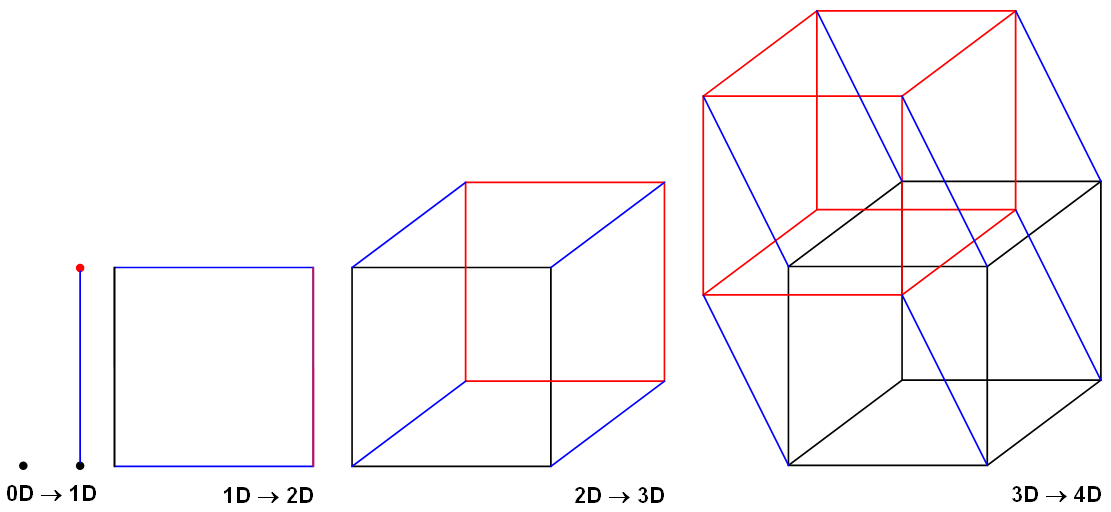
이처럼 vector는 N차원 공간에 사는 존재입니다. 이를 euclidean space라고도 부르죠.
그렇다면 10차원 같이 4차원 이상의 vector는 어떻게 이해해야 할까요?
4차원 이상의 공간은 우리가 눈으로 볼 수 있게 표현하는 것은 불가능합니다.
하지만 이렇게 이해하시면 조금 더 쉬울 것 같습니다.
서론에 등장하는 친구 A와 B가 얼마나 나와 비슷한지 숫자로 나타내는 것을 시도해보는 겁니다.
우리가 생각하는 사람 간 비슷함과 거리감에 영향을 받는 10 가지 요소를 골라봅시다.
나이, 성별, 키, 외국 생활 연차 등 수치화할 수 있는 모든 것을 어찌어찌 뽑아낸다면 친구 A, 친구 B, 그리고 나는 각각 10 개의 숫자로 표현될 수 있습니다.

이는 곧 한 사람이 10차원의 vector로 표현된 거라고 볼 수 있습니다!
물론 사람을 이렇게 간단하게 표현할 수는 없겠지만, 어쨌든 4차원 이상의 벡터가 어떠한 것인지 좀 더 감이 오시나요?
3번째 NLP여정입니다.
사실 저는 고등학교 수학에서 행렬파트가 사라진 비운의 세대입니다...
너무 슬프죠,,, 그래서 다시 해야한답니다.. 흑흑
처음에 해당 내용을 봤을 때 굉장히 놀랬습니다!
표현을 하는 기법이 쉽고 어렵고, 처음 보는 내용을 접하고 이런류의 놀람이 아닌
하나의 수식을, 하나의 현상을 수학적으로 Vector로 표현한다는게 저는 되게 신기했거든요!
그래서 선형대수를 공부하는 지금도 제가 재미를 느낄 수 있는것 같습니다.
사실 선형대수에서 다룰 파트이면서 동시에 별 내용이 없는 주이기 때문에 유클리드 공간(Euclidean space)과 그 외적인 부수내용에 대해 짧게 알아보겠습니다!
유클리드 공간(Euclidean Space)는 수학자 유클리드가 연구했던 평면과 공간을 일반화한 것이다.
유클리드가 생각했던 거리와 길이, 각도를 좌표계에 도입하여 임의 차원의 공간으로 확장한 것이라고 한다.
즉, 표준적인 유한 차원, 실수, 내적 공간을 칭하는 것이다.
나중에 쓰일 개념으로 유클리드 거리라는 것이 있다.
두 점(points)를 잇는 길(path)의 길이(length)를 말한다.
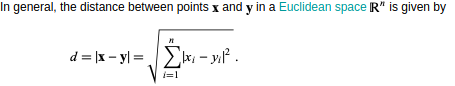
이것이 머신러닝에서 언제, 어떻게 사용되느냐!
나중에 다룰 내용이지만, L2 Norm 이라고 하는게 있다.
정규화 관련 용어로 L1, L2 Norm, Loss, Regularization이라고 하는 것들이 등장한다.
Norm
우리가 가장 쉽게 알고 있는 Norm은 절댓값입니다. Norm이 절대값을 의미한다는 게 아닌 많은 norm 중 하나가 절댓값을 말한다는 거죠. 수학적 정의는 복잡하지만 결국 어떤 값의 크기를 계산하여, 비교가 가능하게끔 하는 함수로 보면 됩니다!

L1 Norm (Mahattan Distance, Taxicab geometry)
위의 그림에서 표시된 것과 같이 L1 Norm은 두 개의 벡터를 빼고, 절대값을 취한 뒤, 합한 것입니다. 예를 들어, x=(1,2,3), y=(-1,2,4)라면 d(x,y)=|1-(-1)|+|2-2|+|3-4|=2+0+1=3입니다.
L2 Norm (Euclidean Distance)
위의 그림에서 표시된 것과 같이 L2 Norm은 두 개의 벡터의 각 원소를 빼고, 제곱을 하고, 합치고, 루트를 씌운 것입니다. 예를 들어, x=(1,2,3), y=(-1,2,4)라면 d(x,y)=root(4+0+1)=root(5)입니다. 사실, 고등수학부터 당연하게 받아들이는 거리 정의가 L2 Norm입니다. 두 개 벡터(점) 사이의 직선거리를 말하는 거죠.
L1 Norm과 L2 Norm의 직관적 차이
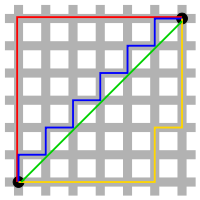
위 그림을 보시면 두 개의 검은 점(벡터)를 잇는 여러 선들이 존재합니다.
벡터 사이의 거리를 재는 서로 다른 Norm을 표기한 셈입니다. 여기서 초록색 선이 우리가 가장 잘 알고있는, Euclidean distance, 즉 L2 Norm입니다. 단 하나의 경우밖에 있을 수 없지요. 그런데 나머지 빨간, 파란, 노란 선은 다른 경로를 움직이지만 사실 모두 같은 L1 Norm입니다. L1 Norm의 수식을 조금만 들여다보면, 당연함을 알 수 있고, 저런 시각적 특성 때문에, Taxicab geometry라고도 불립니다.
L1 Loss

이러한 Norm을 기준으로 만들어진 L1 Loss도 수식이 다르지 않습니다.
두 개의 벡터가 들어가던 자리에 실제 타겟값(y_true)와 예측 타겟값(y_pred)가 들어갔을 뿐이지요.
이는 Least Absolute Deviations(LAD), Least Absolute Errors(LAE), Least Absolute Value(LAV), Least Absolute Residual(LAR) 등으로도 불립니다. L1 Loss는 L2 Loss에 비해 이상치(Outlier)의 영향을 덜 받는, Robust한 특성을 가집니만, 0에서 미분이 불가능합니다.
L2 Loss
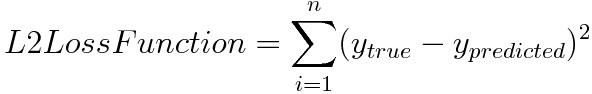
L2 Loss도 다르지 않습니다. 다만 최종적으로 루트를 취하지 않는다는 차이가 있습니다.
이는 Least Squares Error(LSE, 최소자승법)로도 불립니다. 이는 두 개 값의 절대값을 계산하던 L1 Loss와는 달리 L2 Loss는 제곱을 취하기에, 이상치가 들어오면 오차가 제곱이 되어 이상치에 더 영향을 받습니다.
때문에 이상치가 있는 경우에는 적용하기 힘든 방법론입니다.
Regularization
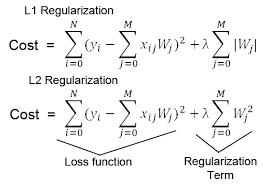
Regularization의 주목적은 모델의 오버피팅(Overfitting)을 줄이고자 하는 것. 즉 모델을 조금더 General하게 만들고자하는겁니다. 이렇게 모델의 일반화 성능을 높이는 방법론에도 Data augmentation, Ensemble model, Dropout, Dropconnect, BatchNormalization, Early stopping, Weight decay, Multi-Task learning 등 정말 여러가지가 존재합니다. 그 중 하나가 나중에 설명할 L1, L2 Regularization입니다. 로우한 개념으로는, 모델을 학습시킨다는건 결국 모델의 Weight matrix를 좋은 방향으로 업데이트해나가는 겁니다. 그런데 이 Weight 중 일부가 학습과정 중 과도하게 커져버린다면, 몇몇개의 인풋에 극단적으로 의존하는 상황이 벌어지고, 이 경우 모델의 일반화 성능은 감소할 것입니다. 때문에 특정 Weight가 과도하게 커지지 않게끔 락(Lock)을 걸어주는 역할을 L1, L2 Regularization이 해줍니다.
출처 : https://jiho-ml.com/weekly-nlp-3/
Week 3 - 지구용사 벡터맨? Vector 기초 잡기!
다양한 사람들을 만나다 보면 어떤 사람은 정말 나와 비슷하다고 (similar) 느낄 때가 있습니다. 반대로 어떤 사람은 정말 거리감 (distance) 이 느껴지지요. 이번주는 사람이 아닌 벡터 (vector)가 무엇
jiho-ml.com
출처 : https://junklee.tistory.com/29
L1, L2 Norm, Loss, Regularization?
정규화 관련 용어로 자주 등장하는 L1, L2 정규화(Regularization)입니다. 이번에는 단순하게 이게 더 좋다 나쁘다보다도, L1, L2 그 자체가 어떤 의미인지 짚어보고자합니다. 사용된 그림은 위키피디아
junklee.tistory.com
'개발 > NLP Trends' 카테고리의 다른 글
| Weekly NLP #05 Review : 얘랑 나랑 얼마나 비슷해? (0) | 2023.02.15 |
|---|---|
| Weekly NLP #04 Review : <왕> minus <남자> plus <여자> = ? (0) | 2023.02.12 |
| Weekly NLP #02 Review : 단어를 가방에 때려 넣으면 문장이 된다. (0) | 2023.02.04 |
| Weekly NLP #01 Review : 컴퓨터에게 언어는 어떤 의미일까? (0) | 2023.01.30 |
| Weekly NLP 스타또..! (0) | 2023.01.29 |



