※ 본 블로그 포스트는 박지호님의 "Weekly NLP" 내용을 채용하여 개인공부를 기록한 포스트입니다.
원작자의 허가를 맡았으며 불법적인 공유가 아님을 미리 알립니다.
단어가 모여 문장을 이루고, 문장이 모여 문서를 이룹니다.
문장을 이해하는데에 단어의 순서는 중요합니다.
왜냐하면 단어의 순서에 따라 의미가 달라지는 경우도 많기 때문이죠.
하지만 그저 이 문장이 어떤 주제를 가지는지만 알고 싶다면 순서가 크게 상관이 없다는 것을 위 예시를 통해 느끼셨을 겁니다. NLP에서는 해결하고자 하는 문제에 따라 문장을 표현하는 방법이 달라질 수 있습니다. 이 글에서는 순서가 상관없는 문장표현방식을 알아보겠습니다.
단어를 가방에 넣어 섞어 버리는 Bag-of-words(BoW)
One-hot vector는 단어를 1개의 column vector로 표현합니다.
만약에 여러 개의 단어의 vector를 단순히 합하여 문장으로 표현하면 어떨까요?
그게 바로 bag-of-words(BoW) vector입니다.
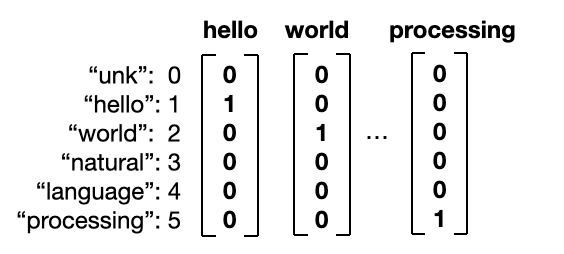
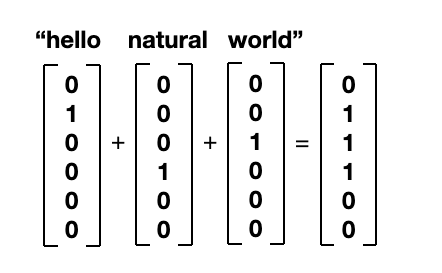
이처럼 단어 3개의 one-hot vector를 합쳐 한 문장을 한개의 column vector로 표현하였습니다.
BoW vector는 Nx1 매트릭스에 문장 안에 포함되어 있는 단어가 몇 번 들어가 있는지 빈도수(frequency)를 표시하는 것입니다.
BoW vector는 단어의 순서를 고려하지 않습니다. 하나의 vector로 뭉개어서 표현하기 때문이죠.
모든 단어를 큰 가방에 던져 넣으면 안에서 섞여버리기 때문입니다.
N-gram : 순서를 그래도 조금은 신경 써야 하지 않을까?
n-gram은 연속된 n개의 단어뭉치를 뜻합니다.
예를 들어, “I love studying machine learning”이라는 문장에 나타나는 bi-gram(n=2)은
[I love, love studying, studying machine, machine learning]총 4개입니다. 이렇게 해서 조금 더 단어 사이의 순서를 신경쓰고 “machine learning”같은 phrase도 고려할 수 있는 방법입니다.
n=2인 n-gram을 이용하여 BoW를 만든다면 학습 데이터 나오는 모든 bi-gram을 vocabulary에 넣어야 합니다.
자연스럽게 단어 수가 많아지면 vocabulary도 커지겠죠? 그렇기에 보통은 n이 너무 크지 않은 2~3정도만 사용합니다.
n-gram은 추후에 language modelling에도 나오는 중요개념이구요!
TF-idf vector : 좀 더 중요한 단어가 있지 않을까…?
term frequency - inverse document frequency(tf-idf)는 단어 간 빈도 수에 따라 중요도를 계산해 고려하는 방법입니다.
잘 생각해보면 학습 데이터가 크면 클수록 자주 쓰이는 단어의 숫자가 커질 것입니다.
영어에서 “the, he, she, it, a”등 article(관사)나 pronoun(대명사)는 꽤나 자주 나오지만 문장의 주제를 파악하는 데 있어서는 중요하지 않을 수도 있습니다. (이를 stop word라고 합니다.)
반대로 “인공지능(AI)”, “자연어 처리(NLP)”같은 단어들은 자주 등장하지 않지만 문서의 주제를 유추하는데 중요한 역할을 할 것입니다.
- term frequency (tf) : 현재 문서(문장)에서의 단어의 빈도수
- document frequency (df) : 이 단어가 나오는 문서(문장) 총 개수
“the, he, she, it, a”같은 단어들은 tf와 df가 둘 다 높을 것입니다.
반대로 “AI, NLP”같은 단어는 tf가 높을 수 있지만, df가 상대적으로 낮겠지요.
tf-idf score는 다음과 같이 정의됩니다.
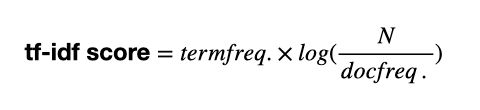
이 수식에서 알 수 있듯이, 기존 BoW에서 문서 내 단어 빈도수를 고려하되, 다른 문서에도 너무 자주 나오는 건 중요도를 낮추어 점수를 계산합니다. df는 분모에 등장하기 때문에 inverse document frequency (idf)라고 합니다.
tf-idf vector는 Nx1 vector 모양의 BoW vector에서 tf점수를 idf로 normalize 한 것으로 이해하시면 됩니다.
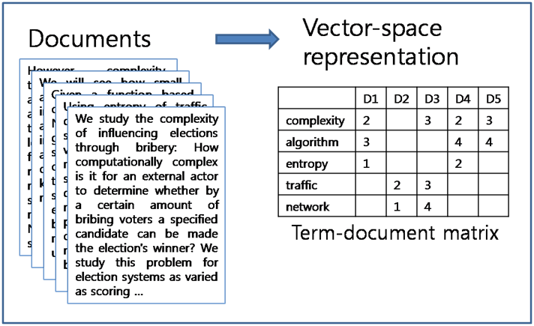
BoW, Tf-idf vector의 단점?
1) 순서가 중요한 문제에는 쓰기 힘들다
Topic Classification이나 Document retrieval같은 task에는 위와 같은 방식이 좋은 성능을 보여줍니다.
즉, 처음에 얘기한 것 처럼 문장의 순서가 중요하지 않은 문제에서 강점을 보인다는 것입니다.
다르게 얘기하면 미세한 정보를 가지고 순서가 중요한 task에는 강점을 보이지 못한다는 말이죠.
2) vocabulary가 커지면 커질수록 쓰기 힘들다
Vocabulary Size가 늘어날수록 커지는 Vector 사이즈입니다.
이는 단어 표현방식인 One-hot vector로부터 시작된 고질적인 문제라고 합니다.
N x 1 column vector로 단어 또는 문장을 표현하기 때문에 vocabulary 크기인 N이 커지면 전체 vector가 엄청 커집니다. (당연한 얘기죠ㅎㅎ) 요런 벡터를 Sparse Matrix(=희소 행렬)라고 합니다. 대다수의 값이 0으로 채워진 행렬을 의미합니다.
3) 단어 간의 관계를 표현하지 못한다
"책상"과 "테이블", "의자"와 "좌석", "아침식사"와 "조찬"은 쓰임새는 다르지만 동의어입니다.
"걷다"는 "볼펜"보다는 "뛰다"와 좀 더 관련이 있습니다. One-hot vector는 각 단어를 각각의 index로 구별하기에 서로의 연관성을 표현할 수 없습니다.
(One-hot vector는 서로 orhogonal하다네요..? 선형대수를 더 공부해서 부연설명을 적도록 하겠습니다!)
NLP여정의 2번째 Step입니다.
지금의 저는 훨씬 많이 나아가서 공부하고 있지만, 블로그 포스팅을 하면서 다시 복습할때가 되면 너무나 즐겁습니다.
이전에 "에이 이정도는 아는거지!"하는 내용도 다시 복습하면서 보게 되면 그렇지 않다는 것을 느끼거든요!
요런게 깨달음의 즐거움인가 싶기도 합니다ㅎㅎㅎ
오늘 복습한 내용은 이전의 One-hot Vector를 바탕으로 한 BoW와 N-Gram, 그리고 TF-IDF입니다.
그 외에 구글링이나 여러가지 내용을 보고 정리를 좀 해보면 아래와 같이 추가적인 내용을 알아볼 수 있을 것 같습니다.
Weekly NLP 02 에서는 순서를 고려하지 않는 단어의 표현방법을 알아본 것이고, 저는 조금 더 추가해서 전체적인 내용을 나름대로 정리해보려고 합니다!
단어의 표현기법에는 아래와 같은 내용으로 구성되어있다고 볼 수 있습니다.
- N-gram
- 카운트 기반의 단어 표현
- 국소 표현 방법(Local Representation)
- 분산 표현 방법(Distributed Representation)
- 연속 표현 방법(Continous Representation)
위에서 나오지 않은 내용을 살펴보면 단어의 표현방법은 크게 국소 표현(Local Representation)방법과 분산 표현(Distributed Representation)으로 나뉩니다. 국소 표현방법은 해당 단어 그 자체만 보고, 특정 값을 맵핑하여 단어를 표현하는 방법이고, 분산 표현방법은 그 단어를 표현하고자 주변을 참고하여 단어를 나타냅니다.
예를들어 puppy(강아지), cute(귀여운), lovely(사랑스러운)이라는 단어가 있을 때 각 단어에 번호를 맵핑하여 부여한다면 이는 국소 표현을 이용한 방법이다.
반면, puppy(강아지)를 표현하기 위해 cute(귀여운), lovely(사랑스러운)이라는 단어를 활용해 puppy는 cute, lovely한 느낌이다로 정의해 나타낸다면 이는 분산 표현을 이용한 방법이다. 즉, 분산 표현방법은 단어의 뉘앙스를 표현할 수 있게 된다.
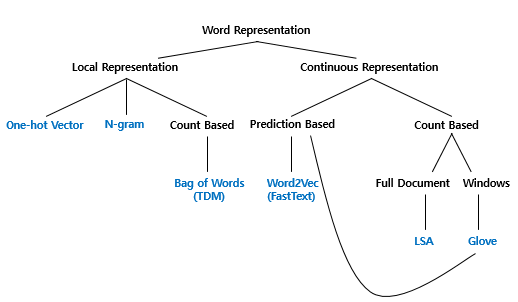
위의 그림은 정민수님의 블로그에서 발췌하였다.
해당 블로그에 의하면 "딥 러닝을 이용한 자연어 처리 입문"에서는 위와 같은 기준으로 단어 표현을 카테고리화 했다고 한다. 이번에 배운 BoW는 국소표현에 해당한다.
아래부터는 해당내용을 공부하기위한 실습코드를 첨부하겠다. (WSL2 구동이슈로 나중에 추가하도록 하겠다...ㅠ)



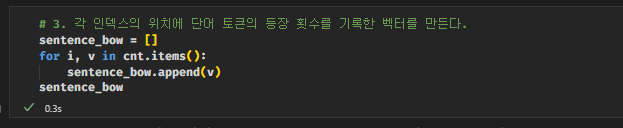

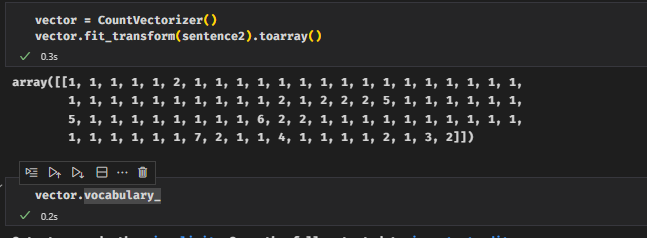
출처 : https://jiho-ml.com/weekly-nlp-2
Week 2 - 단어를 가방에 때려 넣으면 문장이 된다
단어가 모여 문장을 이루고, 문장이 모여 문서를 이룹니다. 문장을 이해하는데 단어의 순서가 중요할까요?
jiho-ml.com
'개발 > NLP Trends' 카테고리의 다른 글
| Weekly NLP #05 Review : 얘랑 나랑 얼마나 비슷해? (0) | 2023.02.15 |
|---|---|
| Weekly NLP #04 Review : <왕> minus <남자> plus <여자> = ? (0) | 2023.02.12 |
| Weekly NLP #03 Review : 지구용사 벡터맨? Vector 기초 잡기! (0) | 2023.02.05 |
| Weekly NLP #01 Review : 컴퓨터에게 언어는 어떤 의미일까? (0) | 2023.01.30 |
| Weekly NLP 스타또..! (0) | 2023.01.29 |



