Ⅰ.Transfer Learning
트랜스퍼 러닝(transfer learning)이란 특정 테스크를 학습한 모델을 다른 테스크 수행에 재사용하는 기법을 가리킨다.
즉, 사람이 새로운 지식을 배울 때 그 사람이 평생 쌓아왔던 지식을 요긴하게 써먹는 것과 같다고 볼 수 있다.
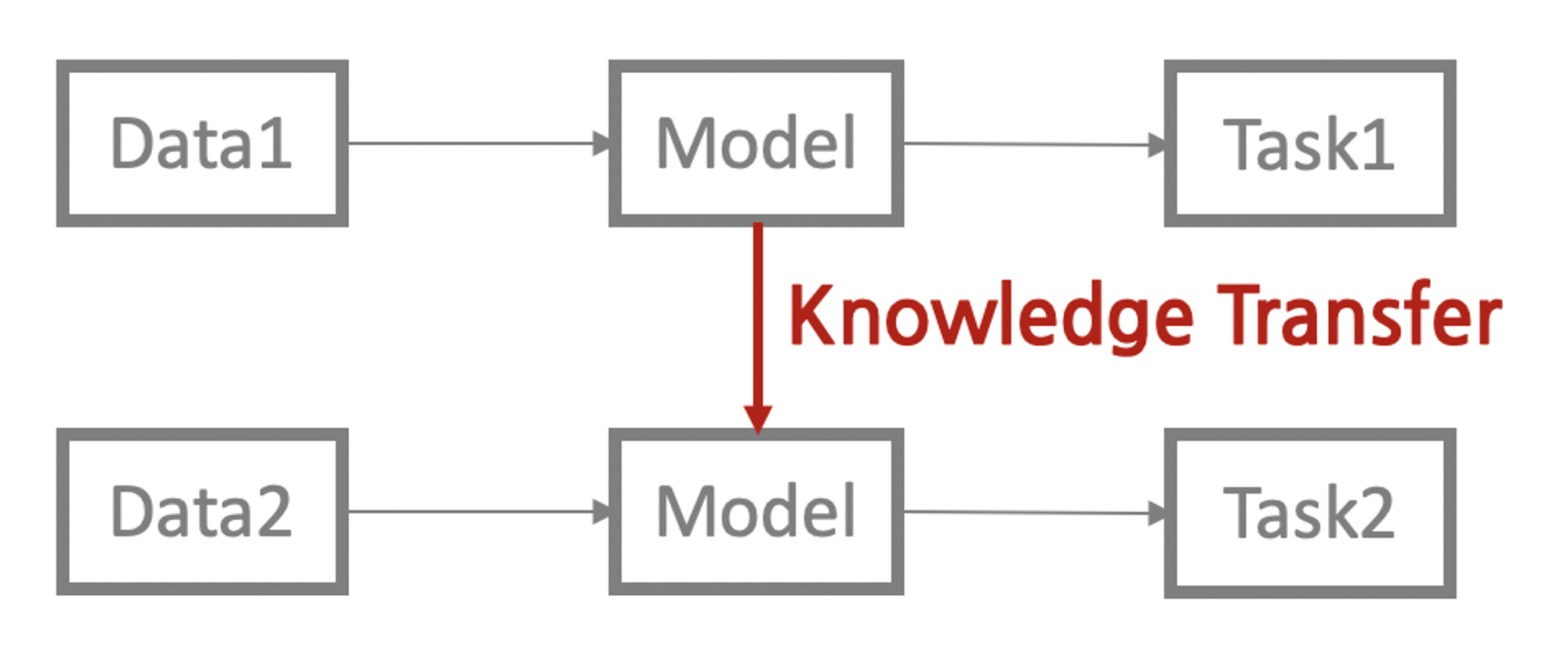
트랜스퍼 러닝을 적용하면 기존보다 모델의 학습 속도가 빨라지고 새로운 테스크를 더 잘 수행하는 경향이 있다.
이때문에 최근 널리 사용되는 작업이며, BERT, GPT등이 바로 해당 기법을 사용한다.
위의 Task1 은 업스트림(UpStream) 테스크라고 부르고 이와 대비된 개념을 다운스트림(DownStream) 테스크라고 한다.
Task1은 다음 단어 맞추기, 빈칸 채우기 등 대규모 말뭉치의 문맥을 이해하는 과제이고, Task2는 문서분류, 개체명 인식 등 우리가 풀고싶은 자연어 처리의 구체적 문제가 해당된다.
업스트림(UpStream) 테스크를 학습하는 과정을 프리트레인(pretrain)이라고 하고, 다운스트림(DownStream) 테스크를 본격적으로 수행하기 앞서 학습한다는 의미에서 이러한 용어가 붙은것으로 생각한다.
Ⅱ. UpStream Task (=업스트림 테스크)
트랜스퍼 러닝이 주목받게 된 것은 업스트림 테스크와 프리트레인 덕분이다. 자연어의 풍부한 문맥(context)을 모델에 내재화하고 이 모델을 다양한 다운스트림 테스크에 적용해 그 성능을 대폭 끌어올리게 된 것이다. 대표적인 예시가 바로 다음 단어 맞추기이다.
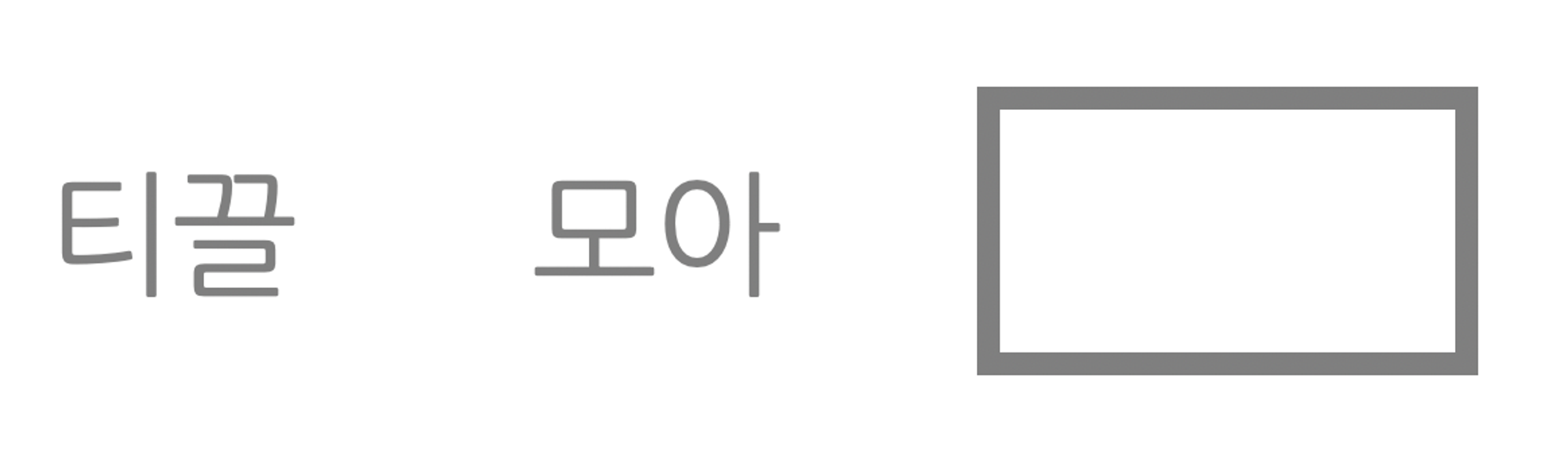
GPT 계열 모델이 바로 이 테스크로 프리트레인을 수행한다. 아래 그림처럼 “티끌 모아”라는 문맥이 주어지고 학습 데이터 말뭉치에 “티끌 모아 태산”이라는 구어(phrase)가 많다고 하면 모델은 이를 바탕으로 다음 단어를 “태산”으로 분류하도록 학습된다.
모델이 대규모 말뭉치를 가지고 이러한 과정을 반복해서 수행하게 되면 이전 문맥을 고려했을 때 어떤 단어가 그 다음에 오는 것이 자연스러운지 알 수 있게 된다. 즉, 해당 언어의 풍부한 문맥을 이해할 수 있게 된다는 것이다. 이처럼 ‘다음 단어 맞추기’로 업스트림 테스크를 수행한 모델을 언어 모델(Language Model)이라고 한다.
언어모델의 학습과정은 일반적인 모델의 학습과정과 다르지 않다. 다만 언어모델에서는 학습 대상 언어의 어휘 수(보통 수만개 이상)만큼 늘어난다. 예를들어 “티끌 모아” 다음 단어의 정답이 “태산”이라면 “태산”이라는 단어에 해당하는 확률은 높이고 나머지 단어에 관계된 확률은 낮추는 방향으로 모델 전체를 업데이트 한다.

또 다른 업스트림 테스크로는 빈칸 채우기가 있다.
BERT 계열 모델이 바로 이 테스크로 프리트레인을 수행한다. 아래 그럼처럼 문장에서 빈칸으로 만들고 해당 빈칸에 들어갈 단어가 무엇일지 맞히는 과정에서 모델이 학습된다.

모델이 많은 양의 데이터를 가지고 빈칸 채우기를 반복 학습하게 되면 앞뒤 문맥을 보고 빈칸에 적합한 단어를 알 수 있다. 이 테스크를 수행한 모델 역시 언어 모델과 마찬가지로 해당 언어의 풍부한 문맥을 내재화할 수 있다. 이처럼 ‘빈칸 채우기’로 업스트림 테스크를 수행한 모델을 마스크 언어 모델(Masked Language Model)이라고 한다. 마스크 언어모델도 학습은 언어모델과 다를게 없다. 위 그림에서 정답이 “모아”라면 “모아”라는 단어에 해당하는 확률은 높이고 나머지 단어에 관계된 확률은 낮추는 방향으로 모델 전체를 업데이트 한다.
우리는 사람이 만든 정답 데이터로 모델을 학습하는 방법을 지도학습(Supervised Learning)이라고 함을 알고있고, 이 방식은 데이터를 만드는 데 비용이 많이 들뿐만 아니라 실수로 잘못된 레이블을 줄 수도 있다는것을 알고있다.
이에반해 다음 단어 맞히기, 빈칸 채우기 같은 업스트림 테스크는 강력한 힘을 지닌다. 뉴스, 웹 문서, 백과사전 등 글만 있으면 수작업 없이도 다량의 학습 데이터를 아주 싼값에 만들어 낼 수 있다. 덕분에 업스트림 테스크를 수행한 모델은 성능이 기존보다 월등히 좋아졌다. 데이터 내에서 정답을 만들고 이를 바탕으로 모델을 학습하는 방법을 자기지도 학습(self-supervised learning)이라고 한다.
Ⅲ. DownStream Task (=다운스트림 테스크)
우리가 모델을 업스트림 테스크로 프리트레인한 근본 이유는 다운스트림 테스크를 잘 하기 위해서이다. 대개 다운스트림 테스크는 우리가 풀어야할 자연어 처리의 구체적 과제들이기 때문이다. 보통 다운스트림 테스크는 프리트레인을 마친 모델을 구조변경 없어 그대로 사용하거나 여기에 테스크 모듈을 덧붙인 형태로 수행한다.
아래 대표적인 다운스트림 테스크의 예제의 본질은 분류(Classification)이다. 다시 말해 자연어를 입력받아 해당입력이 어떤 범주에 해당하는지 확률 형태로 반환한다. 문장생성을 제외한 대부분의 과제에선 프리트레인을 마친 마스크 언어 모델(BERT계열)을 사용한다.
대부분의 다운스트림 테스크의 학습 방식은 모두 파인튜닝(fine-tuning)이며 이는 프리트레인을 마친 모델을 다운스트림 테스크에 맞게 업데이트하는 기법을 말한다. 예를 들어 문서 분류를 수행할 경우 프리트레인을 마친 BERT 모델 전체를 문서 분류 데이터로 업데이트한다. 마찬가지로 개체명 인식을 수행한다면 BERT 모델 전체를 해당 데이터로 업데이트하면 되는 것이다.
아래 대표적인 다운스트림 테스크 유형들을 보자.
문서분류 : 문서분류 모델은 자연어(문서나 문장)를 입력받아 해당 입력이 어떤 범주에 속하는지 그 확률값을 반환한다. 프리트레인을 마친 마스크 언어모델 위에 작은 모듈을 하나 더 쌓아 문서 전체의 범주를 분류한다.

자연어 추론 : 자연어 추론 모델은 문장 2개를 입력받아 두 문장 사이의 관계가 참(entailment), 거짓(contradiction), 중립(neutral) 등 어떤 범주인지 그 확률값을 반환한다. 구체적으로 프리트레인을 마친 마스크 언어모델위에 작은 모듈을 하나 더 쌓아 두 문장의 관계 범주를 분류한다.

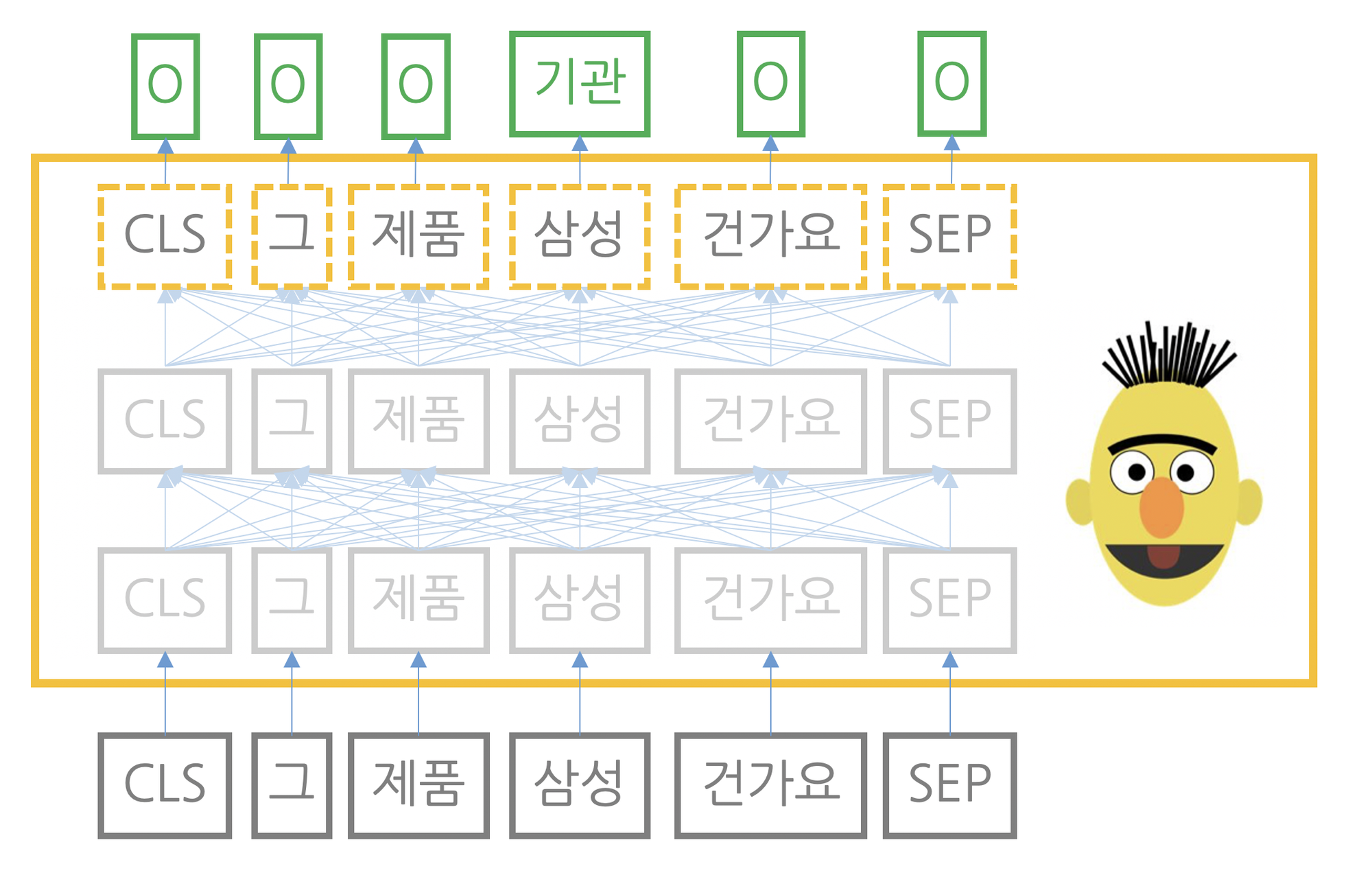
개체명 인식 : 자연어를 입력받아 단어별로 기관명, 인명, 지명 등 어떤 개체명 범주에 속하는지 그 확률값을 반환한다. 프리트레인을 마친 마스크 언어모델 위에 단어별로 작은 모듈을 쌓아 단어 각각의 개체명 범주를 분류한다.
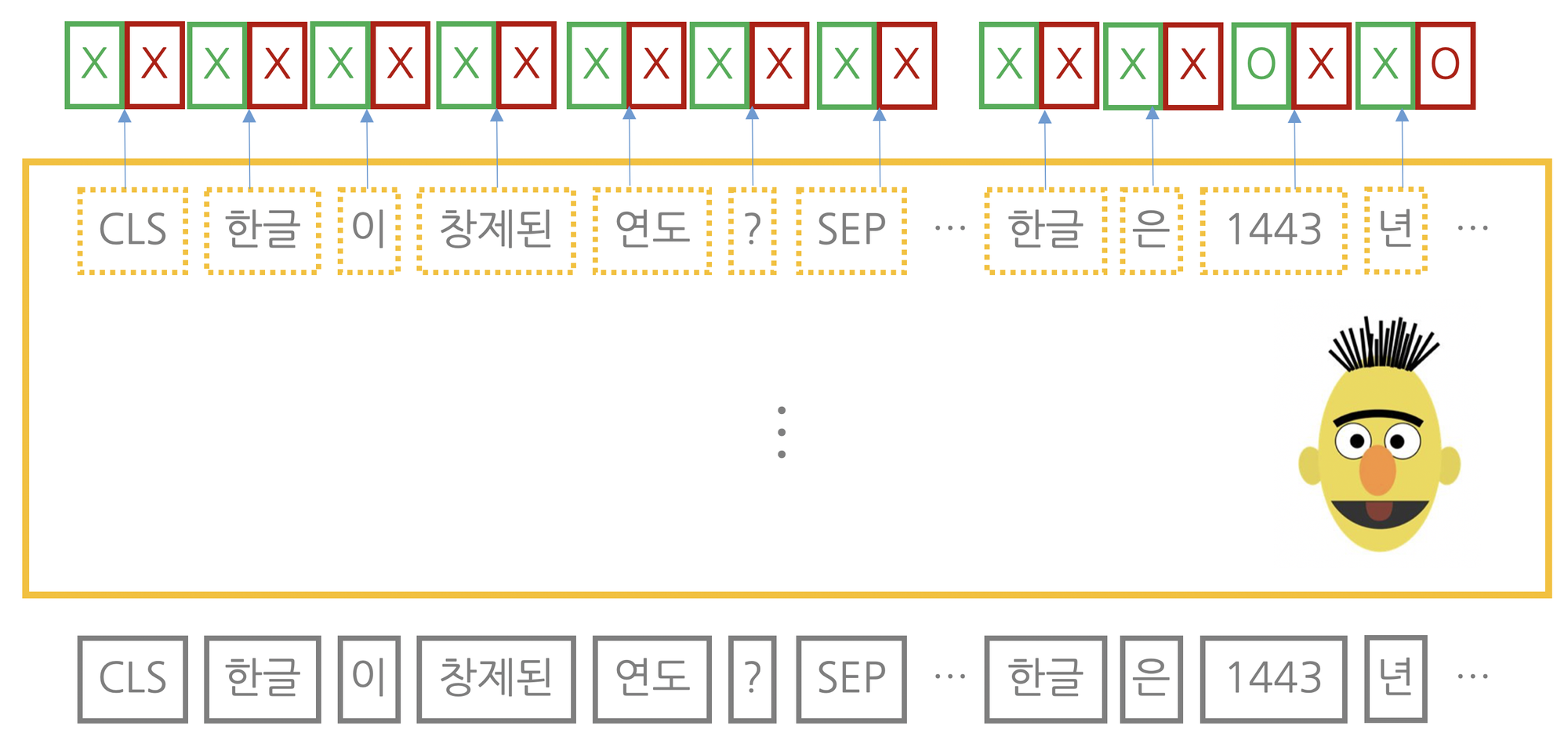
질의응답 : 자연어(질문 + 모델)를 입력받아 각 단어가 정답의 시작일 확률값과 끝일 확률값을 반환한다. 프리트레인을 마친 마스크 언어모델 위에 단어별로 작은 보듈을 각각 더 쌓아 전체 단어 가운데 어떤 단어가 시작인지 끝인지 분류한다.
문장생성 : GPT계열 언어모델이 널리 사용되고, 문장 생성 모델은 자연어(문장)를 입력받아 어휘 전체에 대한 확률값을 반환한다. 이 확률값은 입력된 문장 다음에 올 단어로 얼마나 적절한지를 나타내는 점수이다. 프리트레인을 마친 언어모델을 구조변경없이 그대로 사용해, 문맥에 이어지는 적절한 다음 단어를 분류하는 방식이다.

Ⅳ. 다양한 기법들
앞서 소개한 내용들은 대부분 파인튜닝 방식으로 학습한다. 다운스트림 테스크를 학습하는 방식은 파인튜닝 말고도 다양한다. 크게 다음 3가지가 있다.
- 파인튜닝 (fine-tuning) : 다운스트림 테스크 데이터 전체를 사용한다. 다운스트림 데이터에 맞게 모델 전체를 업데이트 한다.
- 프롬프트 튜닝 (prompt tuning) : 다운스트림 테스크 데이터 전체를 사용한다. 다운스트림 데이터에 맞게 모델 일부만 업데이트 한다.
- 인컨텍스트 러닝 (in-context learning) : 다운스트림 테스트 데이터의 일부만 사용한다. 모델을 업데이트하지 않습니다.
파인튜닝 이외의 방식이 주목받고 있는 이유는 비용과 성능 때문이다. 최근 언어 모델의 크기가 기하급수적으로 커지고 있는데, 파인튜닝 방식으로 모델 전체를 업데이트하려면 많은 비용이 든다. 또한 이미 개발되어있는 모델이 경쟁력 있는 테스크 수행 성능을 보일 때가 많다. 인컨텍스트 러닝에는 다음 3가지 방식이 있다. 다운스트림 테스크 데이터를 몇 건 참고하느냐의 차이가 있을 뿐 모두 모델을 업데이트하지 않는다는 공통점이 있다. 모델을 업데이트하지 않고도 다운스트림 테스크를 바로 수행할 수 있다는 건 꽤나 매력적인 내용이다.
- 제로샷 러닝 (zero-shot learning) : 다운스트림 테스크 데이터를 전혀 사용하지 않고, 모델이 바로 다운스트림 테스크를 수행한다.
- 원샷 러닝 (one-shot learning) : 다운스트림 테스크 데이터를 1건만 사용한다. 모델은 1건의 데이터가 어떻게 수행되는지 참고한 뒤 다운스트림 테스크를 수행한다.
- 퓨샷 러닝 (few-shot learning) : 다운스트림 테스크 데이터를 몇 건만 사용한다. 모델은 몇 건의 데이터가 어떻게 수행되는지 참고한 뒤 이어서 다운스트림 테스크를 수행한다.
한동안 블로깅이 뜸했다가 다시 시작해보려 합니다.
독학으로 NLP를 공부하는 엔지니어의 입장에서 조금 더 깊은 내용으로 다시 리포스팅을 할 예정이니 기대해주세요!
'개발 > NLP' 카테고리의 다른 글
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (17) (0) | 2023.08.04 |
|---|---|
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (16) (0) | 2023.08.03 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (15) (0) | 2023.08.03 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (14) (0) | 2023.08.03 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (13) (0) | 2023.08.03 |



