Ⅰ. SOTA
SOTA는 State of the art의 약자로 현재 최고 수준의 결과를 의미한다.
캐글과 같은 데이터 대회에서 모델 구축을 위해서는 사전학습된 신경망들을 많이 사용하는데, SOTA는 사전학습된 신경망들 중 현재 최고 수준의 신경망이라는 뜻이다. 예를들어, SOTA EfficientDet은 현재 가장 수준이 높은 신경망을 사용한다는 의미이다.
Ⅱ. 언어모델에 대한 평가 체계
ⅰ. 언어 모델의 평가
모델을 설계할 때 가장 중요한 것 중 하나는 “모델을 어떻게 평가할 것인가”이다. 이에 맞게 테스트셋을 구축하고 테스트셋에 대한 평가 지표를 체계적으로 설계함으로써 원하는 테스크에 대한 모델의 성능을 적절하게 평가할 수 있다. NLP는 CV와 다르게 비교적 평가방법이 표준화되어 있지 않다. 2019년 BERT 페이퍼가 발표되면서 GLUE Benchmark가 등장하였고, 이는 현재 영어 관련 NLP 테스크 평가 방법의 표준이 되었다.
ⅱ. GLUE BenchMark
GLUE BenchMark는 General Language Understanding Evaluation이라고 하는데 아래 항목을 포함한 영어 전문 평가방법이다.

- Quora Question Pairs (QQP, 문장 유사도 평가)
- Question NLI (QNLI, 자연어 추론)
- The Stanford Sentiment Treebank (SST, 감성 분석)
- The Corpus of Linguistic Acceptability (CoLA, 언어 수용성)
- Semantic Textual Simiilarity Benchmark (STS-B, 문장 유사도 평가)
- Microsoft Research Paraphrase Corpus (MRPC, 문장 유사도 평가)
- Recognizing Textual Entailment (RTE, 자연어 추론)
- SQUAD 1.1 / 2.0 (질의응답)
- MultiNLI Matched (자연어 추론)
- MultiNLI Mismatched (자연어 추론)
- Winograd NLI (자연어 추론)
이러한 평가체계의 표준화를 통해 BERT이후 등장한 모델들(ALBERT, ELECTRA, RoBERTa, …)이 더 좋은 성능임을 효과적, 효율적으로 입증할 수 있게 되었다.
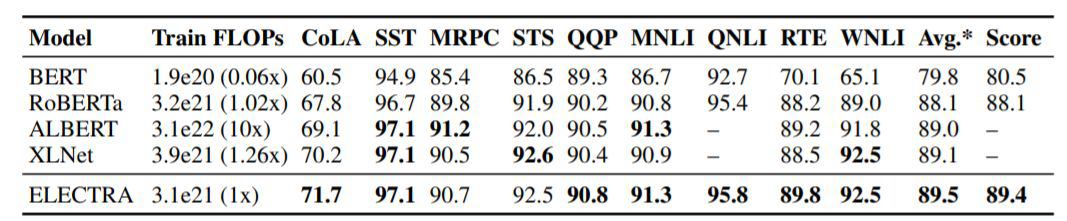
이전까지는 자연어 이해모델에 대한 내용이었다면 GLUE를 통해 생성 모델의 평가도 수행할 수 있다. 자연어 이해 이외에도 자연어 생성 분야에서도 BERT와 같은 pre-trained & fine-tune downstream task 구조가 효과적이었음을 보여준 연구가 등장하였다.
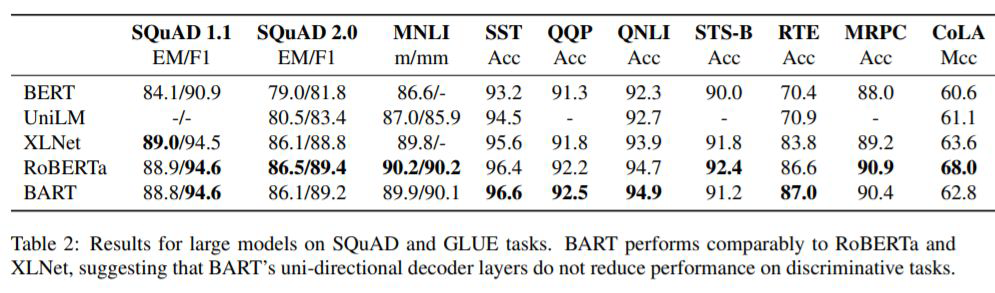
→ T5, BART (단, 여기에서는 인코더 부분보다 디코더 부분에 대한 학습을 위주로 했고, 생성모델이므로 생성이 이루어지는 디코더가 더 중요하다.) 아래 그림과 같이, BART는 생성 이외에도 자연어 이해에 탁월함을 보여주기 위해 자연어 이해 모델 관련 평가 지표를 측정해서 비교해준다.
ⅲ. KLUE (Korean Language Understanding Evaluation)
KLUE는 Korean Language Understanding Evaluation이라고 하며, 한국어 모델의 성능을 평가하기 위한 일련의 데이터셋, 8가지의 다양하고 대표적인 Task를 포함하는 말이다.
위의 자료를 참고하면 되고, 대상항목은 아래와 같다.
- Topic Classification (TC) : 토픽 분류
- Semantic Textual Similarity (STS) : 의미 유사도
- Natural Language Inference (NLI) : 자연어 추론
- Named Entity Recognition (NER) : 개체명 인식
- Relation Extraction (RE) : 관계 추출
- Dependency Parsing (DP) : 의존 구문 분석
- Machine Reading Comprehension (MRC) : 기계 독해
- Dialogue State Tracking (DST) : 대화 상태 추적
GLUE(General Language Understanding Evaluation)라고 하는 11개 task에 관한 DeepMind와 워싱턴 대학교에서 구축한 것이 존재하는데 KLUE가 이의 한국어 버전이라고 생각하면 된다. 각각에 대해 조금 더 자세히 알아보자.
1. Topic Classification (TC)
TC(Topic Classification, 토픽분류)의 목표는 텍스트가 주어지면 해당 텍스트에 대한 주제를 예측하는 classifier를 학습하는 것. 텍스트의 토픽 예측은 NLP분야에서 핵심적인 기능으로 볼 수 있는데, 이는 주로 뉴스처럼 이미 카테고리가 정해진 데이터셋을 통해 구축된다. KLUE-TC에서 사용된 데이터는 16년 1월부터 20년 12월까지 네이버 뉴스에 올라간 연합뉴스의 헤드라인을 모은것이다. 이 헤드라인을 가지고 해당 텍스트가 정치, 경제, 사회, 생활문화, 세계, IT과학, 스포츠 중 어떤 카테고리에 속하는지 예측한다.
해당 Task를 평가할 때는 $macro\;F1\;Score$가 사용된다. 다중분류에 대한 F1 Score를 구할 때는 각 라벨들에 대해 F1 Score를 구한 후 이를 평균내는 방식으로 점수를 계산한다.
2. Semantic Textual Similarity (STS)
STS(Semantic Textual Similarity, 의미 유사도)의 목표는 입력으로 주어진 두 문장간의 의미 동등성을 수치로 표현하는 것이다. KLUE-STS에서 사용된 데이터는 에어비앤비 리뷰, 정책 뉴스 브리핑자료, 스마트 홈 기기를 위한 발화 데이터이다. 에어비앤비 리뷰, 정책 뉴스 브리핑 자료 같은 경우 문장간의 유사성을 추정하기 힘든 경우가 있는데 이때 네이버 파파고를 사용하여 영어로 번역했다가 다시 한국어로 번역하여 유사한 문장 쌍을 생성했다고 한다. 이와 같은 기법을 round-trip translation(RTT)라고 부르는데 이렇게 함으로써 원래 문장의 핵심 의미를 유지하면서 어휘 표현이 살짝 다른 문장을 생성할 수 있었다고 한다.
해당 Task를 평가할 때는 F1 Score와 피어슨 상관 계수가 사용된다. 우선 F1 Score같은 경우, 유사도 3.0을 기준으로 유사하다, 유사하지 않다로 라벨링 후 F1 Score를 구한다고 한다. 피어슨 상관계수는 변수 X, Y가 있을 때 이 두 변수가 어떤 상관관계를 가지는가를 수치로 나타낸 값이다. KLUE-STS에서는 사람이 직접 붙인 라벨값과 모델의 예측 라벨값 간의 선형 상관관계를 측정한다고 한다.
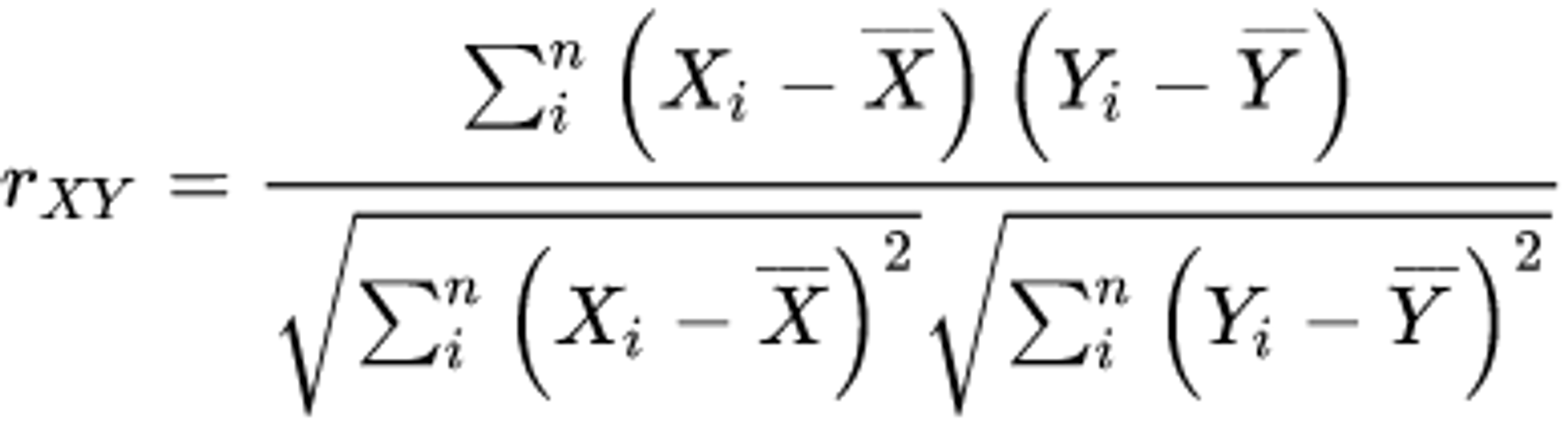
3. Natural Language Inference (NLI)
NLI(Natural Language Inference, 자연어 추론)의 목표는 전제로 주어진 텍스트와 가설로 주어진 텍스트간의 관계를 추론하는 것이다. KLUE-NLI에서 사용된 데이터는 위키트리, 정책 뉴스 브리핑 자료, 위키뉴스, 위키피디아, 네이버 영화리뷰, 에어비앤비 리뷰인데 여기서 조건에 부합하는 10000개의 전제를 추출하여 약 30000개의 문장쌍을 구성했다고 한다. 전제와 가설간의 관계는 가설이 참인 경우(entailment), 가설이 거짓인 경우(contradiction), 가설이 참일수도, 아닐수도 있는 경우(neutral)로 라벨링 되어있다.
해당 Task를 평가할 때는 단순 정확도가 사용된다. 정확도는 모델의 예측 라벨과 실제 정답라벨이 얼마나 정확한가를 나타낸다.
4. Named Entity Recognition (NER)
NER(Named Entity Recognition, 개체명 인식)의 목표는 비정형 텍스트에서 개체의 경계를 감지하고 개체의 유형을 분류하는 것이다. 다시말해 어떤 이름을 가진 단어를 보고 그 단어가 어떤 유형인지 분류하는 것을 말한다. 예를 들어 조직, 시간에 대해 개체명 인식을 수행하는 모델이 있다고 가정해보자. 이 모델에 “커먼컴퓨터는 2018년에 설립되었다.”라는 문장이 들어오면 해당 모델은 커먼컴퓨터(조직), 2018년(시간)을 출력하게 되는 것이다. KLUE-NER에서는 6개의 개체명을 가지고 있는데 이는 사람(PS), 위치(LC), 기관(OG), 날짜(DT), 시간(TI), 수량(QT)로 구성되어 있다. KLUE-NER에서 사용된 데이터는 형식적인 글과 비형식적인 글의 조합을 위해 위키트리와 네이버 영화리뷰가 사용되었다고 한다.
해당 Task를 평가할 때 entity-level macro F1와 character-level macro F1이 사용되었다고 한다. entity-level macro F1의 경우 개체명 레벨에서 얼마나 정확하고 많이 맞췄는지를 평가한다. 이는 한국어의 특성과도 연결이 되는데, 어근에 접사가 결합되어 있는 형태를 띠는 교착어를 의미한다. 따라서 한국어 토큰화를 진행할 때 어근과 접사를 잘 분해해야 하고 이를 평가하는 지표라고 생각하면 된다. character-level macro F1의 경우 모델 예측과 실제 정답 사이의 부분 중첩을 측정하기 위한 점수이다. 이는 각 라벨별 F1-Score의 평균을 통해 구할 수 있다.
5. Relation Extraction (RE)
RE(Realation Extraction, 관계 추출)의 목표는 텍스트에서 단어들 간의 의미론적 관계를 식별하는 것을 말한다. 예를 들어 “김철수는 서울에서 태어났다”라는 문장에서 “김철수”와 “서울”의 관계는 place_of_birth라고 볼 수 있다. KLUE-RE에서 사용된 데이터는 위키피디아, 위키트리, 정책 뉴스 브리핑 자료로 구성되어 있는데 이 데이터들은 no_relation, per:date_of_birth 등 30개의 관계 레이블링이 되어있다. 다른 관계들도 보고 싶다면 하단 레퍼런스 링크를 참조하자.
해당 Task를 평가할 때 micro F1 Score와 area under the precision-recall curve(AUPRC)가 사용되었다고 한다. micro F1 Score는 macro F1 score와 비슷하지만 다른점을 가진다.
여기서 $micro-precision = \frac{TP의\;합}{(TP의\;합)+(FP의\;합)}$이고, $micro-recall = \frac{TP의\;합}{(TP의\;합)+(FN의\;합)}$이다.
AUPRC는 x축을 recall, y축을 precision으로 설정하여 그린 곡선 아래의 면적 값이다. precision과 recall 두 점수 모두 1에 가까울수록 성능이 좋은 모델로 평가하므로 AUPRC점수 역시 1에 가까울수록 성능이 좋다고 평가한다.
6. Dependency Parsing (DP)
DP(Dependency Parsing, 의존 구문 분석)의 목표는 단어 간의 관계 정보를 찾는 것이다.
다시말해 단어와 단어간의 관계를 기본으로 누가 head인지, 의미적으로 지배하는지, 지배당하는지에 대한 관계 정보를 찾는 것을 말한다.

해당 사진을 살펴보면 dependency structure를 구성할 때 규칙이 있다. 이는 Root를 추가해서 단어의 모든 성분의 최종 head는 결국 이 Root가 되도록 설계한다. 사진에서 볼 수 있는 화살표는 head에서 출발하여 dependent를 가리킨다. “철수가”는 “먹었다”의 dependent이며 주어의 관계를 가진다. 이러한 관계를 DEPREL(dependency relation classes)라고 하는데 DEPREL은 NP(Noun Phrase), VP(Verb Phrase)와 같은 9개의 Syntax 태그와 SBJ(Subject), OBJ(Object)과 같은 6개의 Function 태그의 조합으로 이루어진 36개의 TTA Dependency를 따르게 된다.
해당 Task를 평가할 때 UAS(Unlabeled attachment score), LAS(labeled attachment score)가 사용되었다. UAS는 어떤 HEAD를 가리키는지만을 평가하고, LAS는 HEAD와 DEPREL을 모두 계산한다고 한다.
7. Machine Reading Comprehension (MRC)
MRC(Machine Reading Comprehension, 기계 독해)의 목표는 주어진 context와 context에 관한 질문에 답할 수 있는가이다. KLUE-MRC에서 사용된 데이터는 위키피디아, 아크로팬, 한국 경제신문이다.
해당 Task를 평가할 때 EM(Exact Match), ROUGE(character-lvelv ROUGE-W)가 사용되었다. EM의 경우 QA model에서 가장 많이 사용하는 평가 방법으로 실제 답변과 예측 답변이 일치하면 점수를 얻게 된다. 반면 ROUGE의 경우 예측 답변과 실제 답변이 완벽하게 일치하지 않아도 점수를 얻을 수 있다.
8. Dialogue State Tracking (DST)
최근 사람과 컴퓨터 간의 대화 시스템이 점점 주목을 끌고 있다. DST(Dialogue State Tracking, 대화 상태 추적)의 목표는 사람과 컴퓨터의 대화에서 사람이 하는 말의 문맥을 보고 대화 상태를 예측하는 것이다. “서울 중앙에 있는 박물관을 찾아주세요”라는 발화가 들어오면 관광이라는 영역아래 종류-박물관, 지역-서울 중앙을 예측하게되는 형태인것이다.
해당 Task를 평가할 때 JGA(joint goal accuracy)와 slot F1 score가 사용된다. JGA는 매 턴마다 실제 값과 예측 값이 일치하는 정도를 수치화한 값이다. 반면 slot F1 Score는 매턴마다 구한 micro F1 Score의 평균값이다. value pair가 none인 데이터가 있는데 이는 slot micro F1 score를 계산하지 않는다고 한다.
ⅳ. Perplexity
2개의 모델 A,B가 있을 때 모델의 성능을 비교하는 방법이 뭘까? 오타 교정, 기계 번역등의 평가에 대상이 되는 모델을 투입해볼 수 있다. 그후 어떤 모델이 더 높은 성능을 내는지 판단하면 된다. 만약 성능을 비교해야하는 모델이 2개가 아니라면? 다수의 모델에 대해 앞서 말한 방법을 적용시키기에는 시간적 소요가 너무 많이 들게 된다.
그렇기때문에 어쩌면 조금 부정확할 수는 있어도 테스트 데이터에 대해 빠르게 식으로 계산되는 더 간단한 방식이 존재한다. 모델 내에서 자신의 성능을 수치화하여 결과를 내놓는 펄플렉시티(Perplexity)이다.
언어 모델의 평가방법(Evaluation metric) : PPL은 문장의 길이로 정규화된 문장 확률의 역수이다. 문장 $W$의 길이가 $N$이라고 할 때 PPL은 다음과 같은 수식을 가진다.
$PPL(W) = P(w_1,w_2,w_3,\cdots,w_N)^{- \frac{1}{N}} = \sqrt[N]{\frac{1}{P(w_1,w_2,w_3,\cdots,w_N)}}$
문장에 체인룰(chain rule)을 적용하면 아래와 같다.
✍️ Chain Rule 체인 룰(Chain Rule)은 변수가 여러개일때 어떤 변수에 대한 다른 변수의 변화율을 알아내기위해 사용된다. 예를 들어 변수 y가 변수 u에 의존하고, 변수 u가 변수 x에 의존한다고 하면 x에 대한 y의 변화율은 u에 대한 y의 변화율과 x에 대한 u의 변화율을 곱함으로써 계산할 수 있다는 말이다.
$\frac{dy}{dx} = \frac{dy}{du} \times \frac{du}{dx}$
$PPL(W) = \sqrt[N]{\frac{1}{P(w_1,w_2,w_3,\cdots,w_N)}} = \sqrt[N]{\frac{1}{\prod_{i=1}^N P(w_i | w_{i-1})}}$
- 펄플렉시티(perplexity)는 수치가 낮을수록 언어모델의 성능이 좋다는 것을 의미한다.
- 분기 계수(Branching Factor)다만, 주의할 점이 있다. PPL값이 낮다는 것은 테스트 데이터 상에서 높은 정확도를 보인다는 점이지 실제 사람이 직접 느끼기에 좋은 언어 모델이라는 것을 의미하진 않는다. 또한 테스트 데이터가 도메인에 알맞지 않으면 신뢰도가 떨어질 수 있다.
- PPL은 선택할 수 있는 가능한 경우의 수를 의미하는 분기계수(Branching factor)이다. PPL은 이 언어 모델이 특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하고 있는지를 의미한다. 가령, 어떤 LM에 테스트 데이터를 주고 측정했더니 PPL이 10이 나왔다고 해보자. 해당 언어모델은 테스트 데이터에 대해 다음 단어를 예측하는 모든 시점(time step)마다 평균 10개의 단어를 가지고 어떤 것이 정답인지 고민하고 있다고 볼 수 있다. 같은 테스트 데이터에 대해 두 언어 모델의 PPL을 각각 계산한 후 PPL의 값을 비교하면 두 언어 모델 중 PPL이 더 낮은 언어 모델의 성능이 더 좋다고 볼 수 있다.
ⅴ. BLEU Score
BLEU Score는 Bilingual Evaluation Understudy Score라고 하는 성능측정 지표이다. PPL이 번역의 성능을 직접적으로 반영할 수 없는 측정지표라면 BLEU Score는 직접적으로 기계번역의 성능이 얼마나 뛰어난가를 측정할 수 있는 수치이다. 이와 관련된 자세한 내용이 궁금하다면 논문 'BLEU : a Method for Automatic Evaluation of Machine Translation'을 참고하길 바란다.
1. BLEU (Bilinguyal Evaluation Understudy)
BLEU는 기계번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역의 성능을 측정하는 방법이다. 기준은 n-gram에 기반한다. 이는 완벽한 방법이라고 할 수 없지만 아래와 같은 몇가지 이점을 가진다.
- 언어에 구애받지 않고 사용할 수 있다.
- 계산 속도가 빠르다.
- PPL과는 달리 수치가 높을 수록 성능이 더 좋음을 의미한다.
2. NLTK를 사용한 BLEU 측정하기
파이썬의 자연어 처리 패키지 중 NLTK에 BLEU를 계산할 수 있는 메서드가 내장되어있다.
import nltk.translate.bleu_score as bleu
candidate = 'It is a guide to action which ensures that the military always obeys the commands of the party'
references = [
'It is a guide to action that ensures that the military will forever heed Party commands',
'It is the guiding principle which guarantees the military forces always being under the command of the Party',
'It is the practical guide for the army always to heed the directions of the party'
]
print('실습 코드의 BLEU :',bleu_score(candidate.split(),list(map(lambda ref: ref.split(), references))))
print('패키지 NLTK의 BLEU :',bleu.sentence_bleu(list(map(lambda ref: ref.split(), references)),candidate.split()))
실습 코드의 BLEU : 0.5045666840058485
패키지 NLTK의 BLEU : 0.5045666840058485
'개발 > NLP' 카테고리의 다른 글
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (18) (0) | 2023.12.29 |
|---|---|
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (16) (0) | 2023.08.03 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (15) (0) | 2023.08.03 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (14) (0) | 2023.08.03 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (13) (0) | 2023.08.03 |



