Ⅰ. Sequence to Sequence, seq2seq
시퀀스 투 시퀀스는 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에서 사용되는 모델이다. 예를 들어 챗봇(Chatbot)과 기계번역(Machine Translation)이 그러한 대표적인 예씨로서 입력 시퀀스와 출력 시퀀스를 각각 질문과 대답으로 구성하면 챗봇으로, 입출력 시퀀스를 각각 입력문장과 번역문장으로 만들면 번역기로 사용할 수 있다. 그 외에도 내용요약(Text Summeraization), STT(Sppech to Text) 등에서 쓰일 수 있다.
1. 모델의 개요(Overview)
seq2seq는 번역기에서 대표적으로 사용되는 모델이다.

간단히 표현하면 위와 같은 원리로 동작하는데 내부 모습은 아래와 같다.
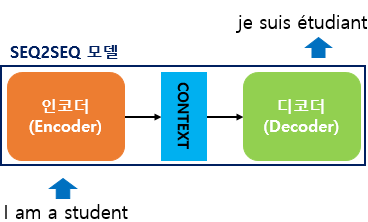
seq2seq는 크게 2개로 구성된 아키텍처로 이루어진다. 바로 인코더와 디코더로인데 인코더는 입력 문장의 모든 단어들을 순차적으로 입력받은 뒤에 마지막에 이 모든 단어정보들을 압축해서 하나의 벡터로 만든다. 이를 컨텍스트 벡터(Context Vector)라고 한다. 컨텍스트는 한국어로 ‘문맥’을 말하며 위 과정을 도식화시키면 아래와 같이 쓸 수 있다.
- 입력 문장의 정보가 인코더로 들어와 하나의 컨텍스트 벡터로 압축한다.
- 인코더에서 압축된 컨텍스트 벡터를 디코더로 전송한다.
- 디코더는 컨텍스트 벡터를 받아서 번역된 단어를 1개씩 순차적으로 출력한다.
2. seq2seq의 동작 과정
인코더 아키텍쳐와 디코더 아키텍쳐의 내부는 사실 2개의 RNN계열 아키텍쳐로 이루어져 있다.
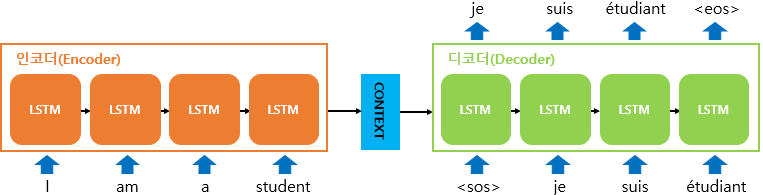
입력문장을 받는 RNN 셀을 인코더라고 하고, 출력문장을 출력하는 RNN 셀을 디코더라고 한다.
인코더를 자세히 보면 입력문장은 토큰화를 통해 단어 단위로 쪼개지고 단어 토큰은 각 시점의 입력이 된다. 인코더 RNN셀은 모든 단어를 입력받은 뒤에 인코더 RNN셀의 마지막 시점의 은닉 상태를 디코더 RNN 셀로 넘겨주는 데 이것이 컨텍스트 벡터이다. 이 컨텍스트 벡터는 디코더 RNN 셀의 첫번째 은닉 상태로 사용된다.
(1). 테스트 단계
디코더는 초기 입력으로 문장의 시작을 의미하는 심볼 <sos>가 들어간다.
디코더는 <sos>가 입력되면 다음에 등장할 확률이 높은 단어를 예측한다.
위와 같은 과정을 반복하여 문장의 끝을 의미하는 심볼인 <eos>가 다음 단어로 예측될 때까지 반복한다.
(2). 훈련 단계와 교사 강요
seq2seq는 훈련과정과 테스트 과정의 작동방식이 다르다.
훈련과정에서 디코더에게 인코더가 보낸 컨텍스트 벡터와 실제 정답인 상황이 나와야 된다고 정답을 알려주면서 훈련해야 한다. 이를 교사 강요(teacher forcing)라고 한다.
반면 테스트 과정에서는 앞에서 설명한 과정과 같이 디코더는 오직 컨텍스트 벡터와 현 시점의 단어만을 입력으로 받은 후 다음에 올 단어를 예측하고 그 단어를 다음 시점의 RNN 셀의 입력으로 넣는 과정을 반복한다.
(컨텍스트 벡터는 사실 인코더에서의 마지막 RNN 셀의 은닉 상태값을 말하는 것이며, 이는 입력 문장의 모든 단어 토큰들의 정보를 요약해서 담고있다고 할 수 있다.)
3. 임베딩 층(Embedding layer)
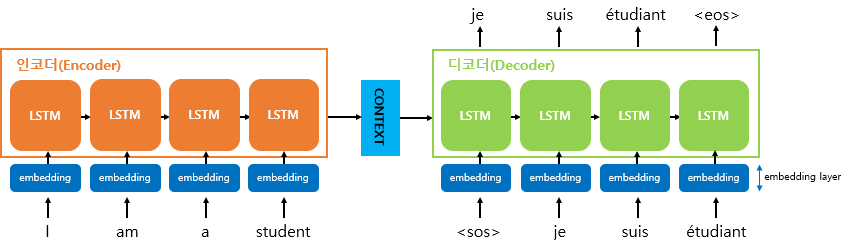
기계는 텍스트보다 숫자를 잘 처리하고 자연어 처리에서 텍스트를 벡터로 바꾸는 방법으로 워드 임베딩이 사용된다고 공부했다.
즉, seq2seq에서 사용되는 모든 단어들은 워드 임베딩을 통해 임베딩 벡터로서 표현된 임베딩 벡터입니다.
예를 들어 I, am, a, student라는 단어들에 대한 임베딩 벡터는 위와 같은 모습을 가지게 된다.

위 참고그림은 쉽게 표현하고자 사이즈를 4로 하였지만, 보통 실제 임베딩 벡터는 수백 개의 차원을 가질 수 있다.
4. 디코더
디코더는 인코더의 마지막 RNN 셀의 은닉 상태인 컨텍스트 벡터를 첫번째 은닉 상태의 값으로 사용한다. 디코더의 첫번째 RNN 셀은 이 첫번째 은닉 상태의 값과, 현재 t에서의 입력값인 <sos>로부터, 다음에 등장할 단어를 예측하고 이 예측된 단어는 다음 시점인 t+1 RNN에서의 입력값이 되며, 이 t+1에서의 RNN 또한 이 입력값과 t에서의 은닉 상태로부터 t+1에서의 출력 벡터.
즉, 또 다시 다음에 등장할 단어를 예측하게 될 것이다. 이제 디코더가 다음에 등장할 단어를 예측하는 부분을 확대해보자.

'개발 > NLP' 카테고리의 다른 글
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (18) (0) | 2023.12.29 |
|---|---|
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (17) (0) | 2023.08.04 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (15) (0) | 2023.08.03 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (14) (0) | 2023.08.03 |
| NLP Load : 맨땅에 헤딩하는 NLP 공부일지 (13) (0) | 2023.08.03 |



