
사실,, 요 행사를 진행한지 좀 되었는데요.. 열심히 필기하면서 재밌게 보다가 놓친부분이 있어서 영상이 재업로드될 때까지 기다렸습니다ㅎ 시작을 해볼게요!! 강연 순서는 다음과 같습니다.
1. 회사 및 프로그램 소개
2. 강연
a. 한국어 오픈액세스 LM 동향
b. Llama-2-Ko/Yi-Ko/Solar-Ko 등 프로젝트 소개
c. 학습 데이터 수집, 전처리 과정, 토크나이저 제작 과정 및 시행착오
d. 오픈모델의 사용성과 라이센스
3. Q&A

강연을 리뷰하기에 앞서 저는 한국어 언어모델 연구과 특정 Domain에 언어모델이 적용될 때 어떻게 하면 높은 성능을 취할 수 있을까? 에 굉장히 관심이 많습니다. 특이하게도 어느 한 Domain을 정해놓기보단 통용되는 성능에 더 관심이 많구요. 궁극적으로는 산업전반적인 부문에서, 그리고 이것이 사람의 입장에서 인공지능을 더 잘 다루고 유효한 성능을 이끌어 낼 수 있는 중요한 Key-Point가 된다고 생각합니다! 제가 HCI(Human Computer Interaction)과 Human Centered NLP에 관심을 가진 계기이죠ㅎㅎ
본 강연은 현 데이터드리븐에서 근무하고 계시는 이준범님께서 진행해주셨구요. 업계에서는 Beomi라는 닉네임으로 더 유명합니다!!
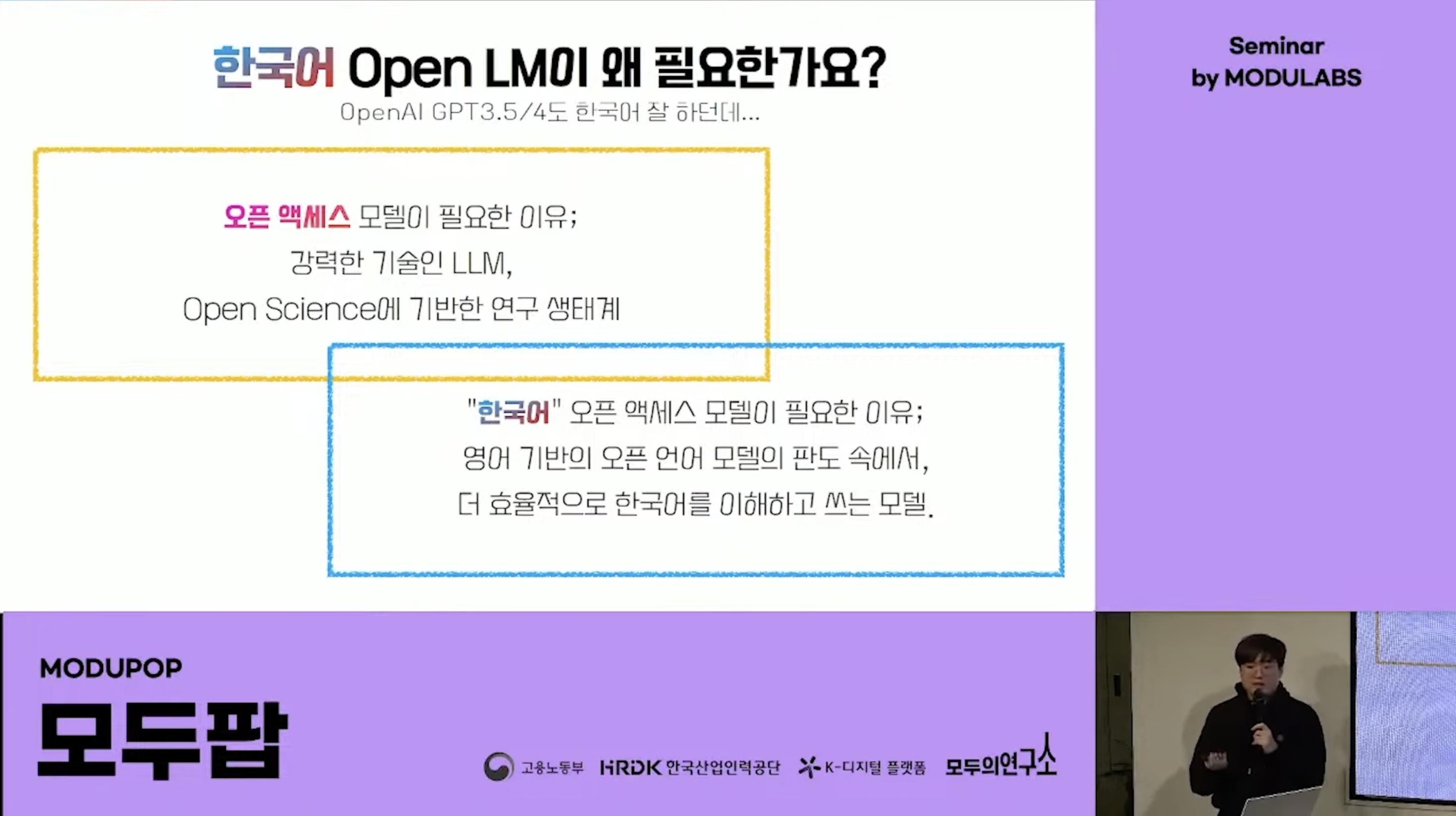
오픈액세스 모델에 한국어 오픈액세스 모델이 부분집합으로 속해있습니다. 현존하는 OpenAI의 GPT3.5와 4.0이 한국어도 잘 하지만 결국에는 대부분이 English기반이라 더 한국어에 특징을 효과적으로, 효율적으로 잘 이해하고 쓸 수 있는 모델이 필요하다고 생각합니다!
결국 태생의 한계를 벗어나긴 어렵달까요ㅎㅎ 단순히 눈에 보이는 평가지표의 수치적 성능으로만 판단하기보다는 구조적으로, 사용된 데이터의 면모에서 원천적으로 한국어에 적합한 모델과 그 활용이 필요하다고 말씀드리고 싶습니다ㅎㅎ
또한, 그것은 발표를 진행해주신 이준범님께서도 동일한 말씀을 해주시네요..! 역시 제 롤모델이십니다 :)

오픈 액세스 LM은 Pre-training과 Fine-tuning의 크게 2가지 방식으로 발전이 되어가고 있다고 합니다. 물론, 강화학습을 이용한 DPO(Direct Preference Optimization), PPO(Proximal Policy Optimization) 나 RLHF(Reinforce Learning from Human Feedback)와 같은 방식도 많이 등장하고, 사용되고 있습니다! 물론 그럼에도 크게 분류하자면 Pre-training과 Fine-tuning으로 분류할 수 있다는 것이죠ㅎㅎ 강화학습을 이용한 학습방식에 관련된 레퍼런스는 최하단을 참고하시면 주석과 링크 달아놓을게요😆
또 Instruct Tuning이라는 용어가 있어요! 알것같으면서도 애매한 개념이었는데 '지시조정'이라고 부르기도 합니다! Fine-Tuning의 일종으로 사용자의 질문 및 지시를 포함한 프롬프트에 대하여 적절한 답변으로 구성된 데이터셋을 가지고 Pre-trained Large Language Model (사전학습된 대규모 언어모델)을 fine-tune하는 방식입니다.

이게 또 데이터셋의 크기도 커지고, 언어모델의 사이즈도 커지다보니 학습에 드는 비용도 정말 만만치 않은데요, 오우... 위에 보면 단위가 말도 안되게 차이가 나죠. 물론 제 생각이긴 합니다만 영어 베이스의 언어모델 시장에 비해 한국어 베이스의 언어모델이 확장되려면 Finetuned 방식이 더 활성화되고 많이 사용되어야 한다고 생각합니다ㅎㅎ
요부분에서도 중요하게 고려해야하는 요소가 있어요. 바로 PEFT라고 하죠. PEFT는 Parameter-Efficient Fine-Tuning of Billions-Scale Models on Low-Resource Hardware라고 하는 기술입니다. 이 기술은 빅 사이즈의 데이터를 이용하여 pre-train하고 downstream task에 맞춰 fine-tuning함과 동시에 한정된 자원과 비용으로 전체 모델을 fine tuning 하는 효과가 나게끔 유도하는 방법입니다. 요건 너무 중요한 내용입니다. 사실 인공지능과 모델 학습에 있어 비용관리와 자원관리는 빼놓을 수 없거든요. 그래서 따로 포스팅하도록 할게요. 물론 참고자료는 아래에 달아놓겠습니다.

오.. 지금이야 당연하게도 받아들여지는 사실을 이분은 새로운 시작점으로 작용했군요..! 항상 근원적인 궁금증이 그 사람의 가치를 더 빛내는 것이 아닌가 싶습니다..! 크으.. 멋있다..🤩

사실 DAPT와 TAPT는 한창 BERT가 나올때 자주 쓰였던 말이라고 해요. "BERT와 같은 모델을 가지고 특정한 Domain 분야에대한 지식을 넣어서 학습을 시키자!"고 한 것이 Domain Adaptaion이고, NSMC 감성분류 모델, MRC와 같은 것들이 Task Adaptiation인 것이죠. 여기서 중요한것이 Domain입니다! 일반적으로 LM은 영어기반이 많다고 했죠. 이 경우 한국어 역시 하나의 Domain으로 바라본다는 말입니다!

여기서 중요한 내용이 하나 나오는데요, DAPT를 수행했을 때 발생하는 문제점이 기존 Domain을 까먹는 문제가 있다고 합니다. 또한 이 문제가 현재의 언어모델 (= Casual LM)을 학습하는데 동일하게 나타난다네요..! 즉, 이준범님께서는 영어모델을 가지고 한국어로 DAPT를 수행하고 이때 영어를 까먹고 한국어만 잘하게 되는 요 현상을 최소화 하는 것이 프로젝트의 본 목적이라고 하시네요! 댑악...!
아, 그리구 Continual Learning, Continual Pretraining 모두 동일한 표현이고, '사전학습된 모델에서 추가적으로 더 학습을 한다'가 Continual Learning이고 이것을 대용량 코퍼스로 베이스 모델을 만들기 위해 하는 작업이 Continual Pretraining이라고 합니다. 사실상 혼용되서 사용된다고 합니다.

본격적으로 프로젝트 내용을 알려주신다고 합니다!!! 요 내용도 분량이 꽤 많을것 같으니..ㅎㅎ 포스팅을 2개로 나눠볼게요.
2편에서 이어집니다 👉👉👉 Go!
👉 Youtube 모두의 연구소 : 모두를 위한 한국어 오픈 액세스 언어모델_못다한 이야기 - 이준범님 (데이터드리븐, AI 연구원)
👉 Scatter LABS : RLHF 외에 LLM이 피드백을 학습할 수 있는 방법은 무엇이 있을까?
RLHF 외에 LLM이 피드백을 학습할 수 있는 방법은 무엇이 있을까?
RLHF 외에 Human feedback을 학습할 수 있는 방법론들에 대해서 소개하고 핑퐁팀에서 실험한 경험을 공유합니다.
tech.scatterlab.co.kr
👉 questionnet tistory blog : RLHF, 언어모델과 강화학습의 만남
LLM Trend Note (4) InstructGPT : RLHF, 언어모델과 강화학습의 만남
RLHF의 탄생배경 모든 일이 그렇듯, 어느날 갑자기 없던 게 생겨나진 않습니다. 우리가 보는 건 땅 위에 싹이 불쑥 튀어 나와 하루가 다르게 쑥쑥 자라나는 모습이지만, 싹이 트기 바로 직전까지
questionet.tistory.com
[Hugging Face] PEFT에 대해 알아보자
본 포스트에서는 자연어처리 분야에서 입지전적인 위치를 가지고 있는 Hugging Face에서 새로이 개발한 🤗PEFT :Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware의 설명 문서를 번역하
4n3mone.tistory.com
'개발 > NLP Trends' 카테고리의 다른 글
| [후기] 모두를 위한 한국어 오픈액세스 언어모델 못다한 이야기 (feat. 모두연) #2 (1) | 2024.02.10 |
|---|---|
| Weekly NLP #08 Review : 스팸 이메일 분류기 만들기 (0) | 2023.02.28 |
| Weekly NLP #07 Review : 머신러닝과 NLP는 왜 함께 갈까 (0) | 2023.02.23 |
| Weekly NLP #06 Review : 박대리, 얘네 문서들 주제별로 분류해오게 (0) | 2023.02.22 |
| Weekly NLP #05 Review : 얘랑 나랑 얼마나 비슷해? (0) | 2023.02.15 |



