
LoRA 논문에 대한 리뷰포스팅으로 돌아왔다! 혹시모를 자료를 위해 공식 Github Repo를 첨부하니 확인해보라! https://github.com/microsoft/LoRA 여길 들어가보면 알 수 있다 😆
LoRA를 리뷰하기전에 왜 요런 기법이 등장했는지 파악하면 더 알기좋다.

요즘도 그렇지만 1,2년전부터 ChatGPT 열풍이 불었다. 그덕에 LLM에 대한 관심도가 급상승하였는데 새로운 기술이 등장할때마다 사람들은 원천기술보단 응용을 어떻게 해서 본인에게 어떠한 도움이 되느냐를 더 주목하기 마련이다. LoRA가 화두에 떠오른 부분은 하나의 문제점으로부터 시작되었는데, 바로 LLM을 Full-Finetuning하는 것이 너무 한계점이 명확하다는 부분이었다. 상식적으로 자본과 컴퓨팅 리소스, 데이터가 충분한 회사단위이면 모를까 개인이 직접 LLM을 Finetuning해본다는것은 매우 어려운일이다. 지금부터 소개할 LoRA는 기존의 파라미터보다 훨씬 적은 파라미터수를 가지고 Finetuning하는 방법론이며 이는 더 적은 리소스를 가지고도 기존과 동일한 성능의 Finetuning을 가능케 한다. 조금 더 알아보자.
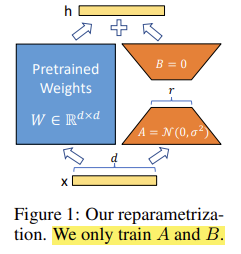
요 그림이 사실 알파이자 오메가이다. 정말 논문쓰시는 분들은 어쩜 저리 찰떡인 피규어들을 만들어내시는지,, 정말 대단하다. 근데 정말로 직관적으로 잘 표현한 피규어라고 생각한다. 기존의 가중치를 그대로 활용한 Full-Finetuing이 파란색 박스로 보면 되고, 주황색 사다리꼴 2개가 LoRA 방법론을 적용한 Finetuning이라고 보면 된다.
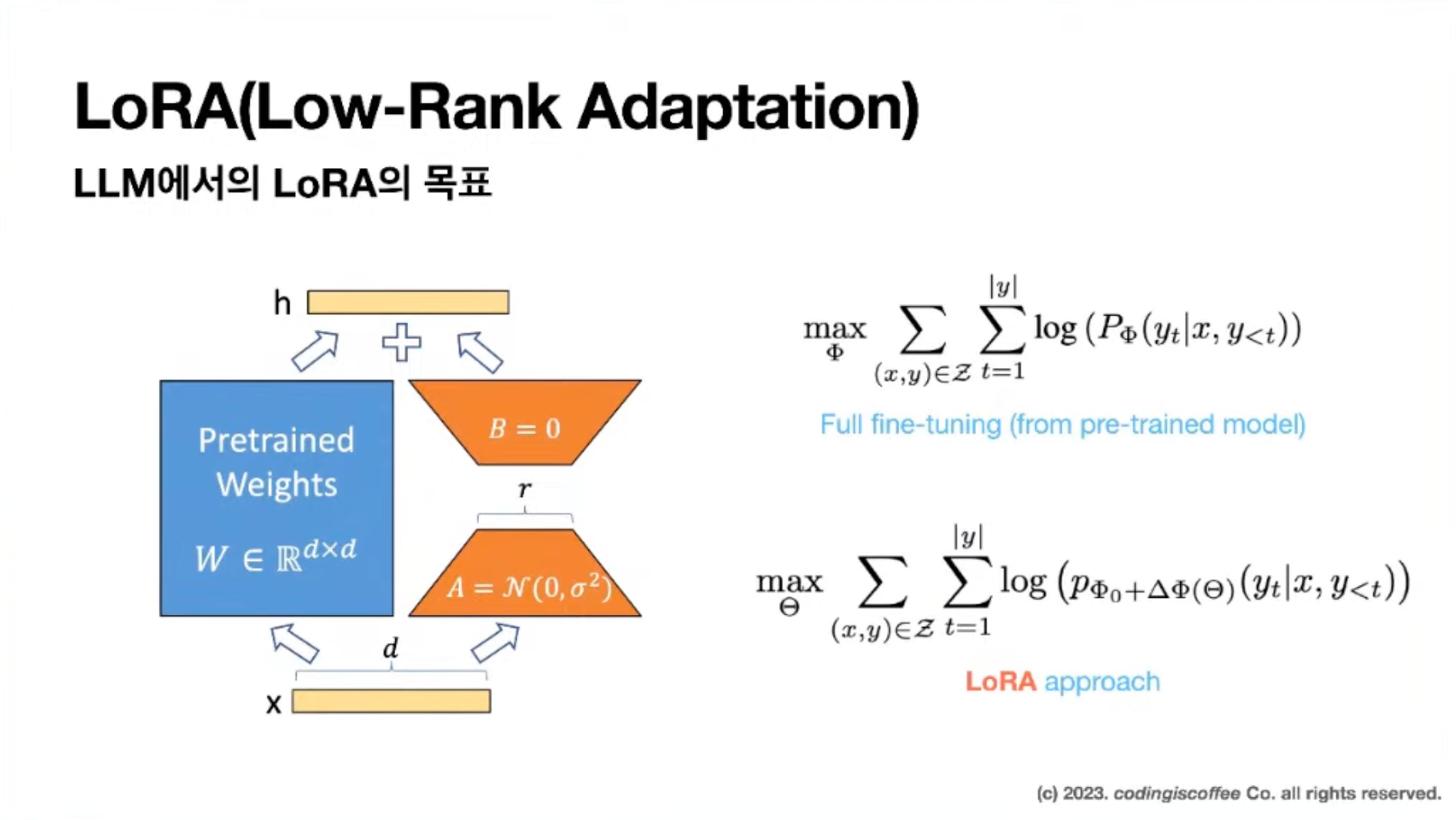
해당 논문에선 Language Model 로 한하여 설명한다! $\Phi$로 parameterized 되어있는 pre-trained lm (= $P_{\Phi} (y|x)$)가 주어졌음을 가정하고 시작한다. 일반적인 LM은 Auto Regressive Model 이고 이것이 $P_{\Phi} (y_t | x, y<t)$ 로 표현된 것. (여기서 $t$는 time이 맞다.) $P_{\Phi} (y|x)$는 GPT와 같은 Generic한 모델로 이해하면 될 것 같다. 이제 요 모델을 가지고 Downstream task에 맞게 adaptation하는 상황을 가정해보자. 이 Downstream task를 adaptation하기 위해서는 context-target pair의 training dataset을 가지고 이것을 $Z = \{(x_i,\;y_i)\}_{\;i=1,\cdots, N}$와 같이 Notation한다. 여기서 $x_i$와 $y_i$는 token sequences라고 한다. 물론 Downstream task마다 구성은 다르다. 예를들어 NL2SQL의 경우 $x_i$는 Natural Language, $y_i$는 $x_i$에 맞는 SQL Command일것이고, Text Summerization의 경우 $x_i$는 paragraph, $y_i$는 $x_i$에 맞는 summerization 내용일 것이다.
Full fine tuning의 경우 아래 수식을 따라간다.
$$ \max_{\Phi} \sum_{(x,y) \in Z} \sum_{t=1}^{|y|} log(P_{\Phi}(y_t|x,\;y_{<t})) $$
model의 pre-trained weights $\Phi_0$으로 initialize 될 것이고 학습이 진행되면서 가중치를 $\Phi_0 + \Delta \Phi$로 업데이트 한다. 각기 다른 downstream task를 위해서 $|\Phi_0|$ dimension 크기의 $|\Delta \Phi|$을 매번 재학습시켜야 하니 결론적으로 parameter수가 크면 클수록 굉장히 코스트가 많이 든다는 문제점이 발생하는 것이다. 예를들어 GPT-3의 경우 1750억개의 parameter수를 가지니 각 downstream task에 맞게 adaptation시키는 작업의 부하가 굉장히 많이 걸리게 될 것이다.
$$ \max_{\Theta} \sum_{(x,y) \in Z} \sum_{t=1}^{|y|} log(P_{\Phi_0 + \Delta\Phi(\Theta)}(y_t|x,\;y_{<t})) $$
LoRA는 업데이트 해야하는 파라미터를 $\Delta\Phi = \Delta\Phi(\Theta)$와 같이 row-rank로 encode하여 훨씬 작은 size의 parameter $\Theta$로 대체 학습하는 것을 말한다.
즉 요걸 내 나름대로 다시 정리해보면 아래와 같다.
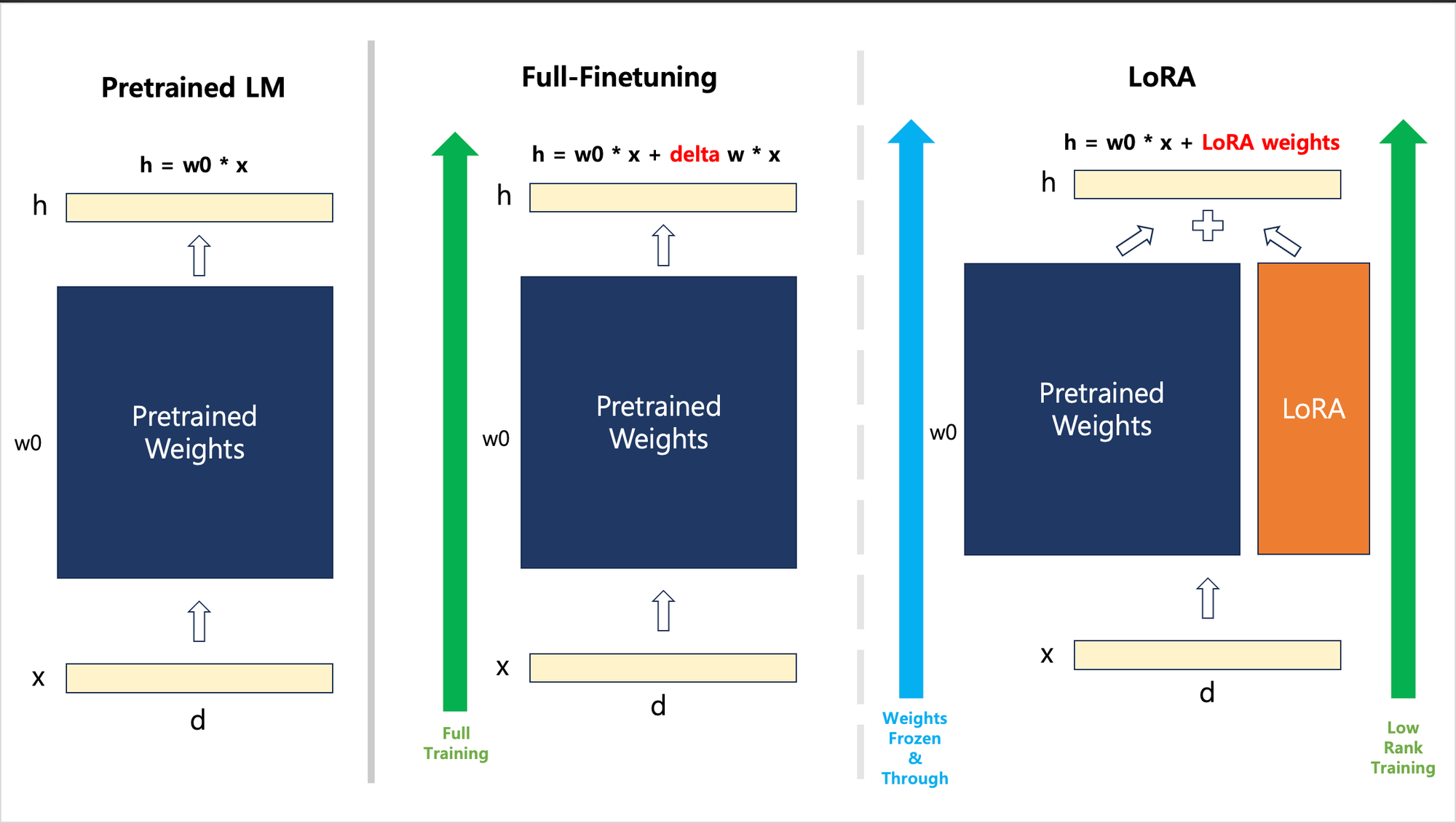
이렇게 볼 수 있을 것 같다. 즉, LoRA를 아래와 같이 정리해서 말할 수 있겠다.
기존의 모델과 그 모델의 $weights$를 가지고 어떠한 Downstream task로 Adaptation할 때 Full-Finetuning방식은 해당 $weights$를 그대로 학습시켜야 해서 Time/Space Complexity가 굉장히 많이 소모되니 기존 $weights$에다가 이를 $Low-Rank$로 표현하여 Parameter를 Minimize하여 합쳐서 학습을 시켜도 충분히 기존의 Full-Finetuning에 가까운 성능을 보인다.
'개발 > 논문' 카테고리의 다른 글
| Upstage - Survey on Large Language Models (0) | 2023.12.22 |
|---|---|
| Transformer - Attention is All You Needs (0) | 2023.11.24 |
| NLP, LLM, Agent, Trends, etc... 논문 리스트 (0) | 2023.08.03 |
| 무식한 개발자의 논문리뷰 : (Basic) (1) | 2023.05.08 |



